

Guides
Apr 13, 2025

Albert Mao
Co-Founder

Transform your organization with AI
Discover how VectorShift can automate workflows with our Secure AI plarform.
Sales productivity relies on focusing time on leads with the highest chance of conversion. By implementing lead scoring, sales teams can boost conversion and pipeline generated.
In this article, we will walk through a redacted pipeline that VectorShift built for the sales team of an enterprise B2B technology company.
Designing the Workflow
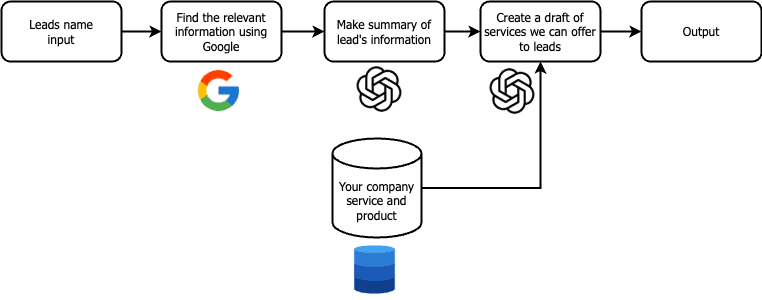
Here’s the overall design of the workflow looks like:
Compile and centralize all of your company information into a knowledge base. Within the workflow, we will then leverage this information to assess whether your company’s product / services are a good fit for a given lead.
Build a workflow that utilizes 1) online data and 2) data from the knowledge base to assess whether a given prospect is a good fit for your company.
Deploy an interface on the workflow so end users can use the tool.
1. Building a Knowledge Base
Add data about your company’s product and services in a knowledge base.
Step 1: Go to the “Knowledge” menu on the left, and click “New” on the top right.
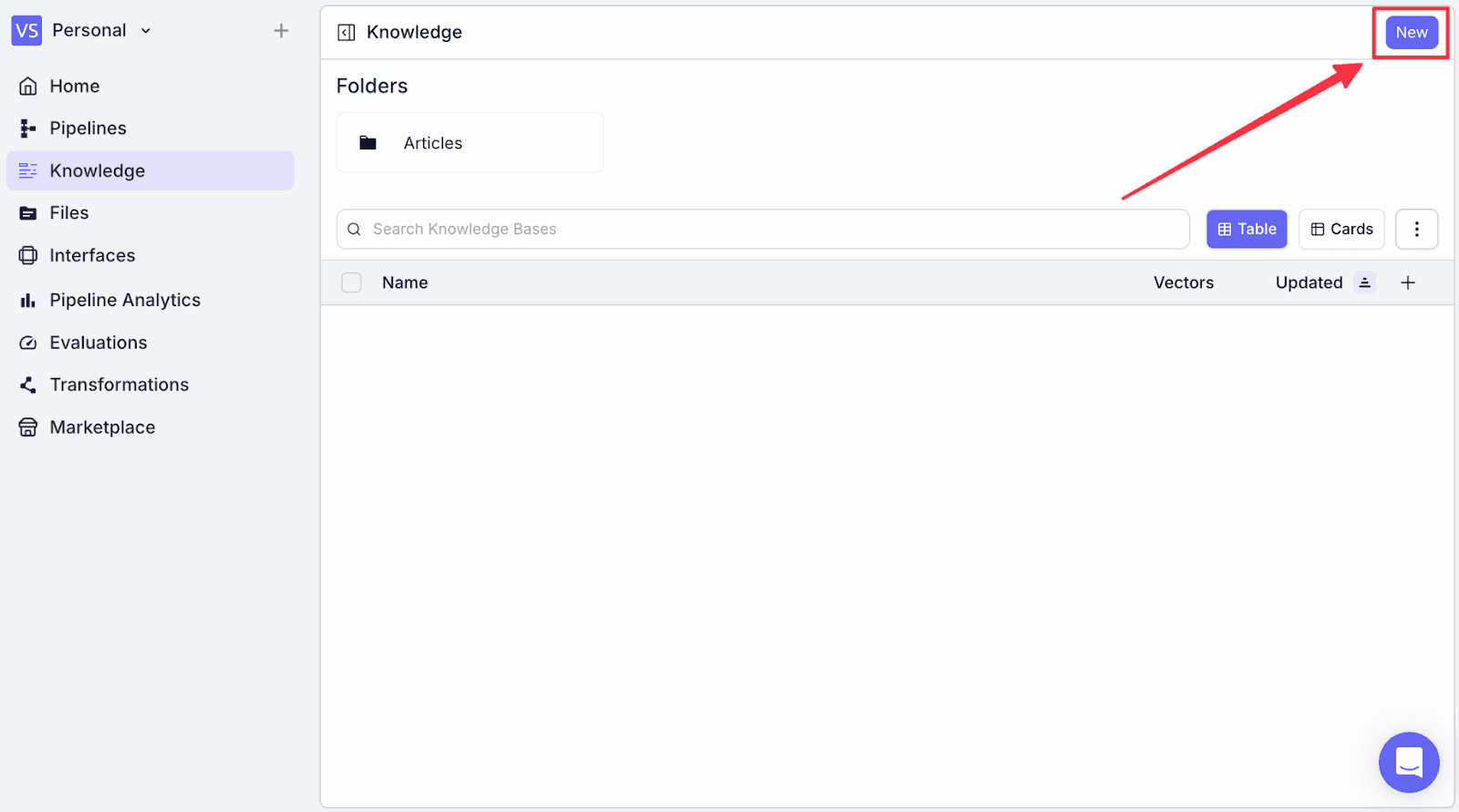
Step 2: Name the knowledge base, then click “Create”.
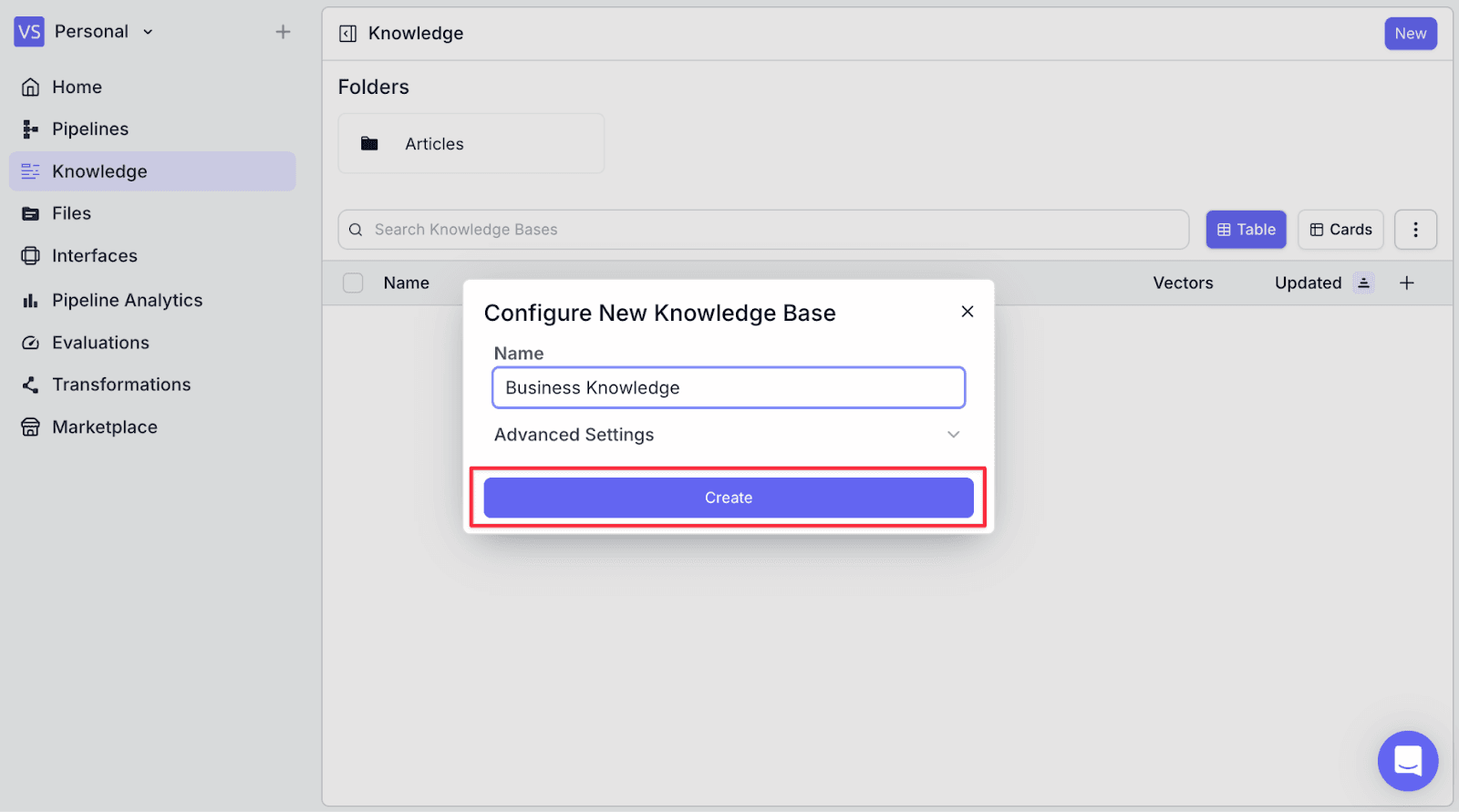
Step 3: You can add relevant documents in multiple ways:
Import documents directly from your computer
Connect to cloud storage services like Google Drive or Dropbox
Scrape from existing URL
As you import your data, VectorShift will automatically index the information, making it easily retrievable.
Now click “Add Document” on the top right, then click “Scrape URL”.
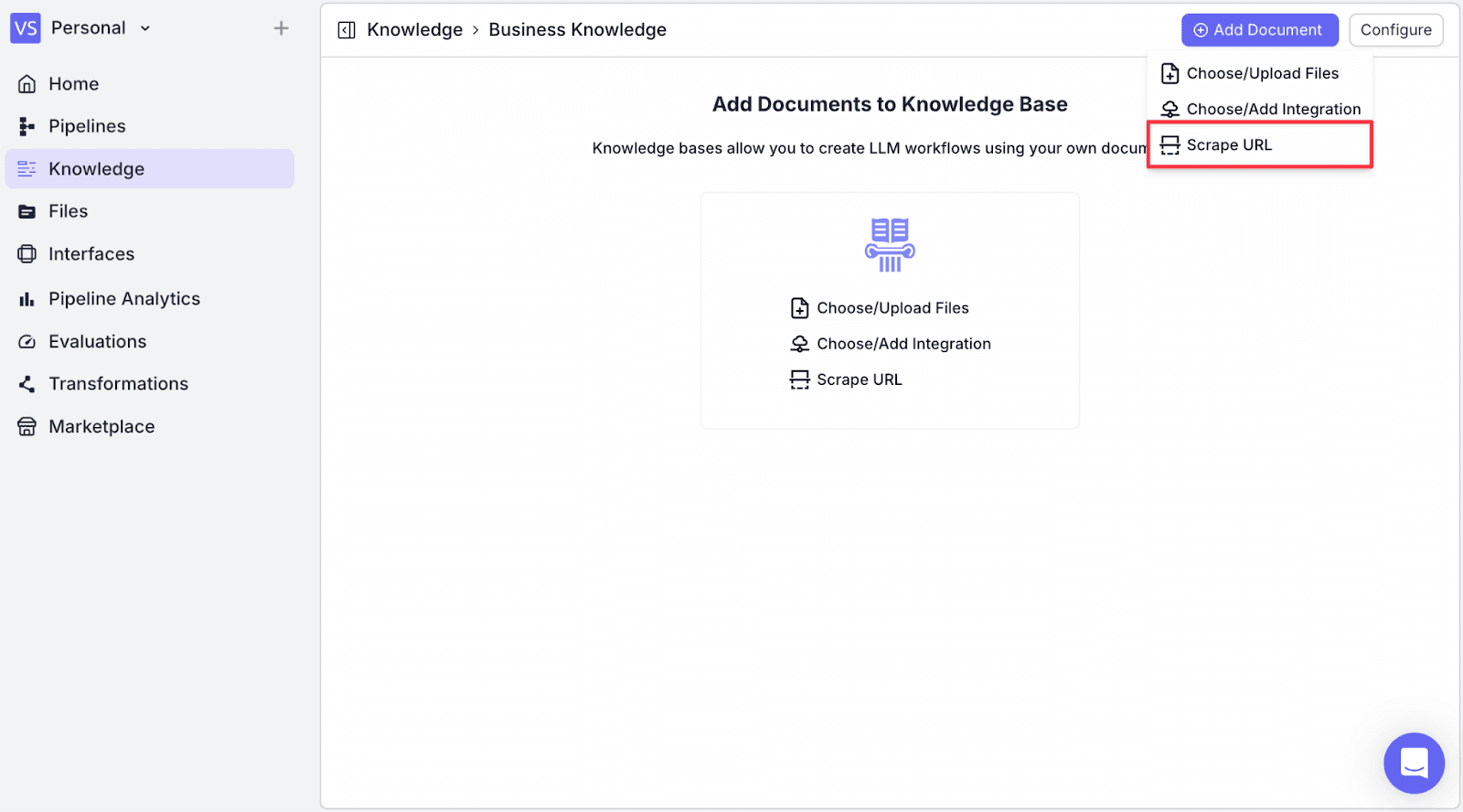
Step 4: Check on “Recursive” and set the Max URLs as many as you want. In this context, we will keep it at “10”. Recursive allows the pipeline to scrape sub-links.
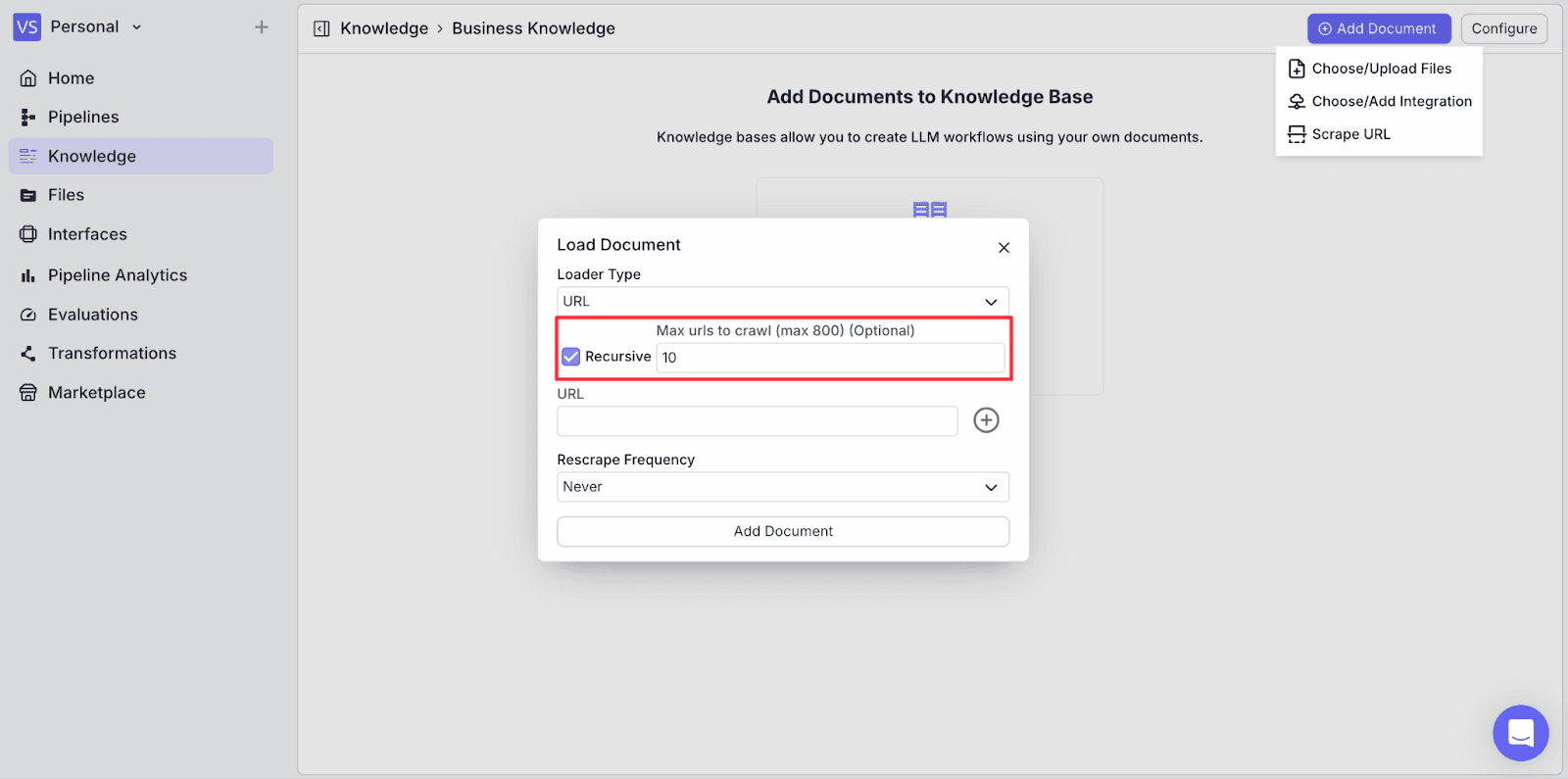
Step 5: Put the “URL” of your product or services, and change the “Rescrape Frequency” to “Weekly”.
This will enable VectorShift to detect updates to your website at a given time interval. If there are changes, the new data will be automatically embedded.
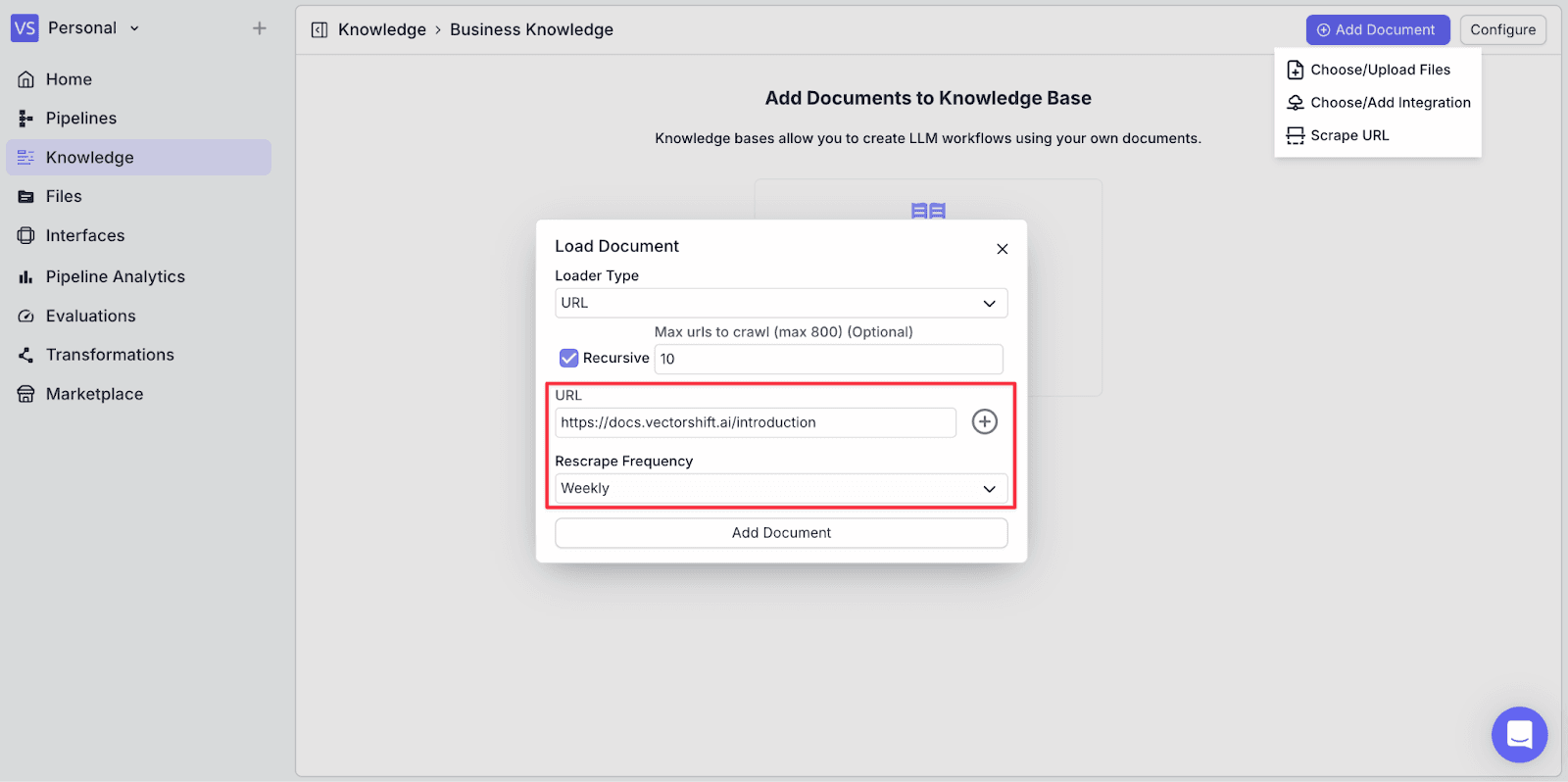
Step 6: Click “Add Document” to add the URL's content to the knowledge base.
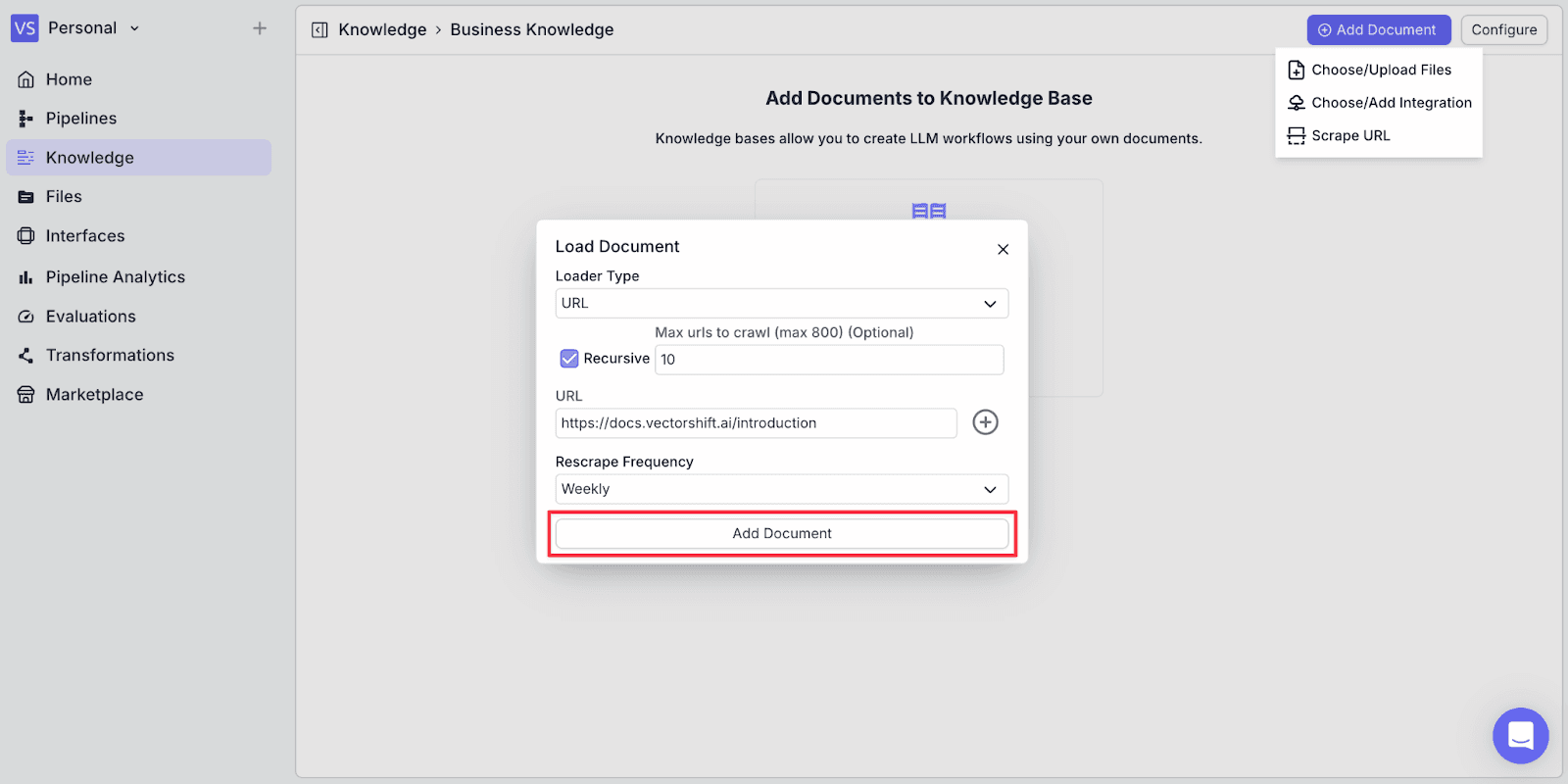
Now, you can see the scraped URL has been added to the knowledge.
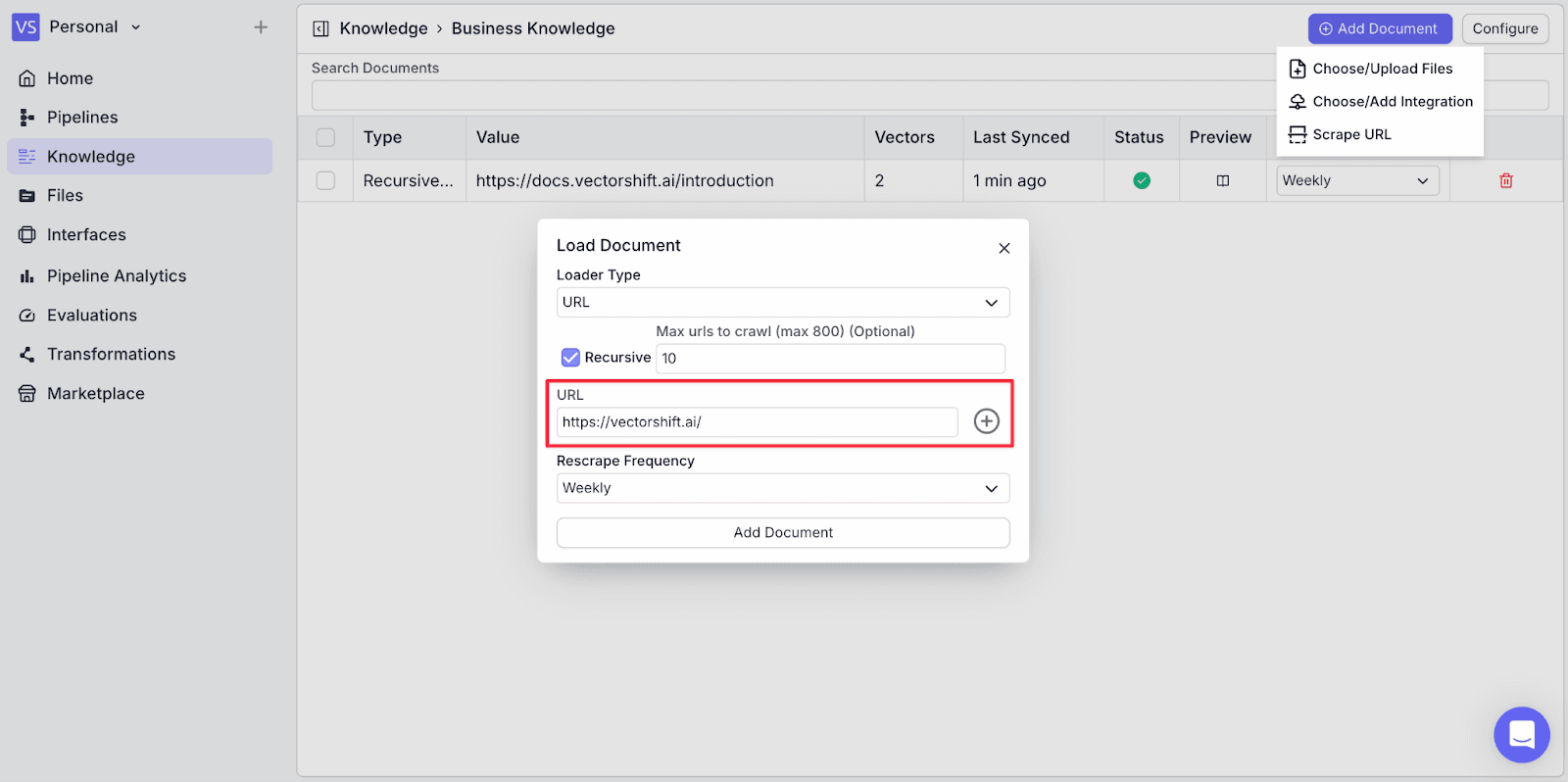
Step 7: Now add another URL by clicking “Scrape URL”. This time, add another link to be scraped.

2. Designing the Pipeline
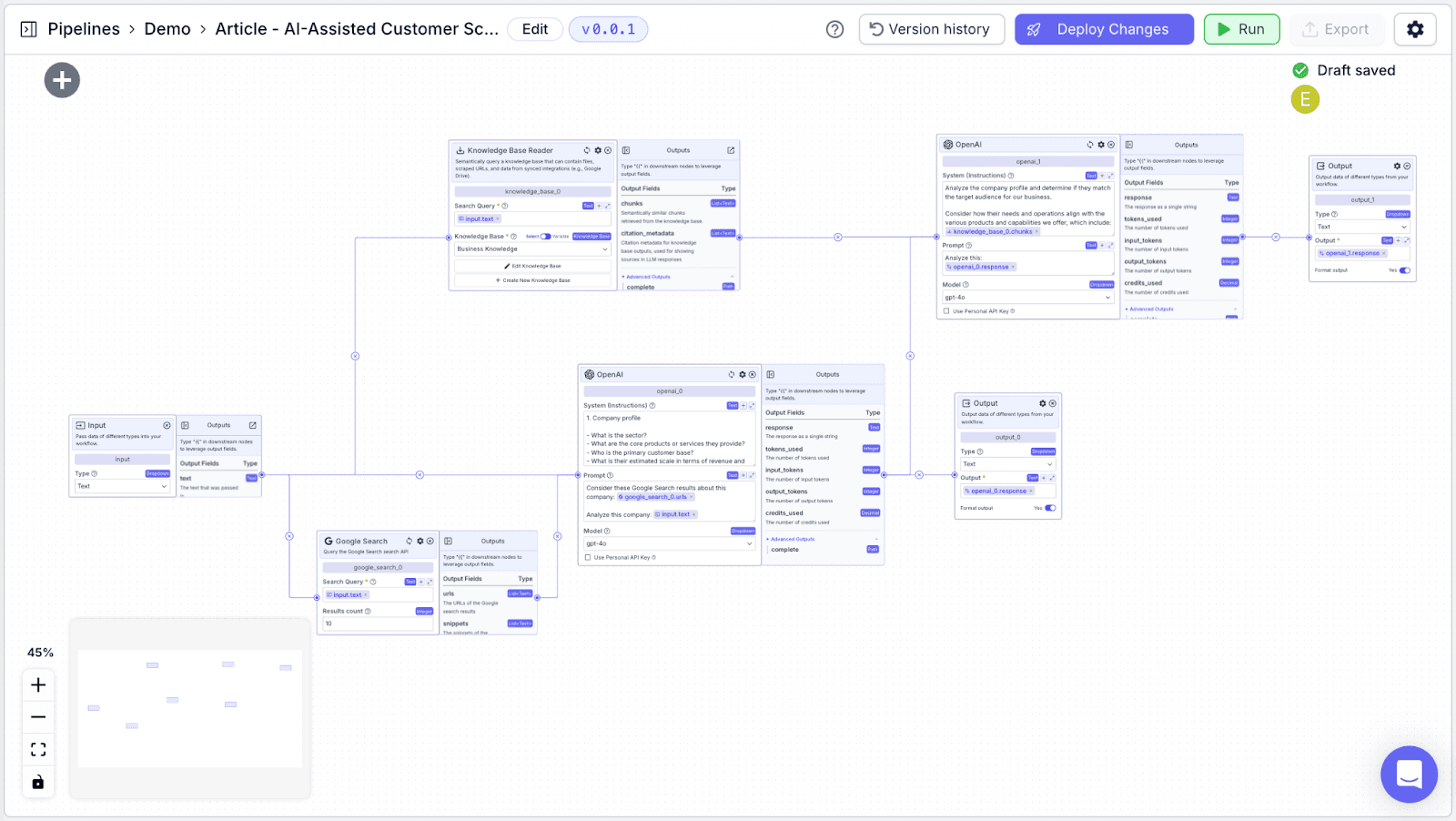
We will utilize the following nodes in the pipeline:
Input Node: To allow for the user to input a company name (the lead to be scored).
Knowledge Base Node: Access data stored in the knowledge base from step 1.
Google Search Node: To find relevant online data about the inputted company.
LLM Nodes: To assess whether the lead is a good fit based on data from the google search and the knowledge base.
Output Nodes: Display the lead score to the user.
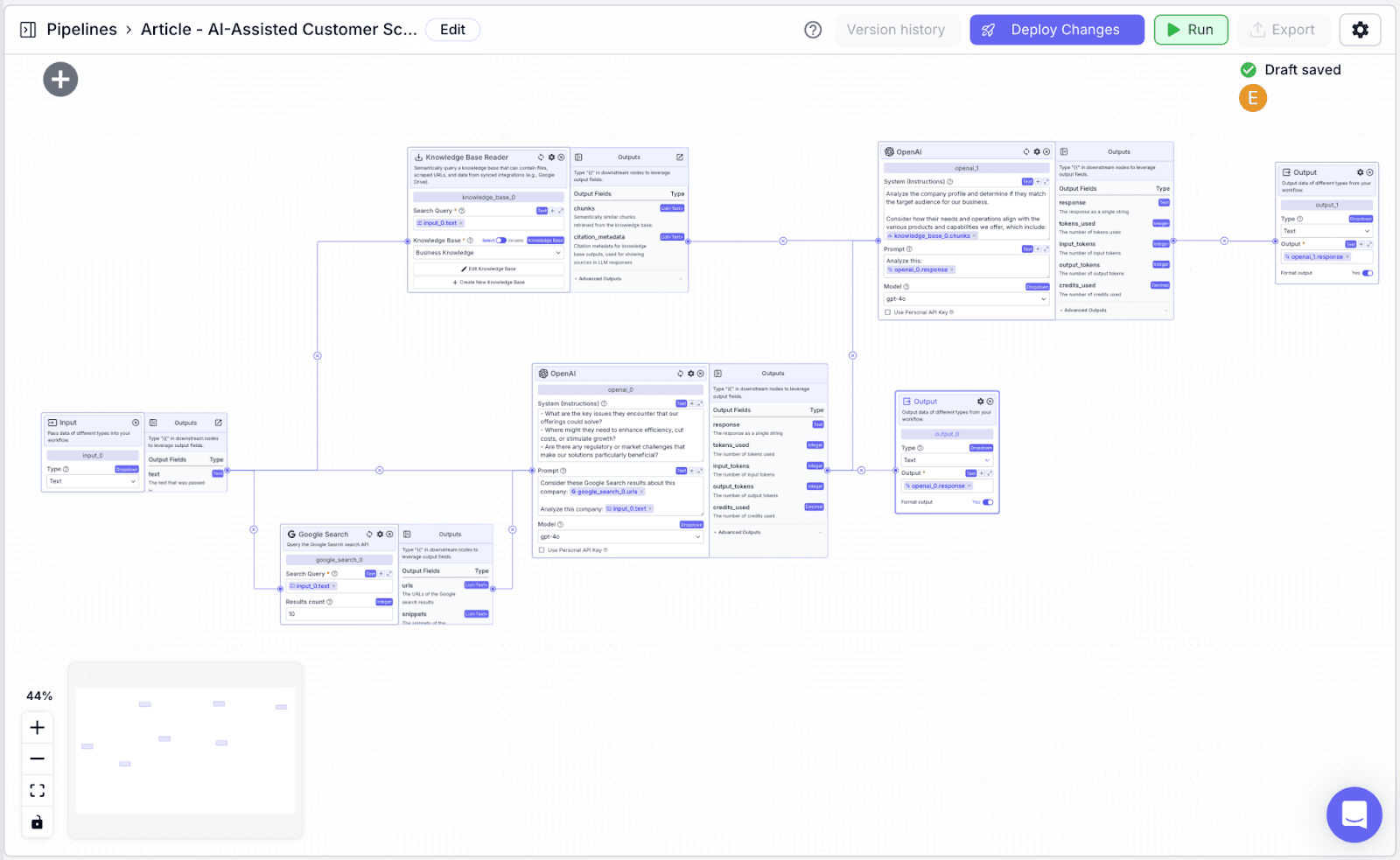
Working with Nodes in VectorShift
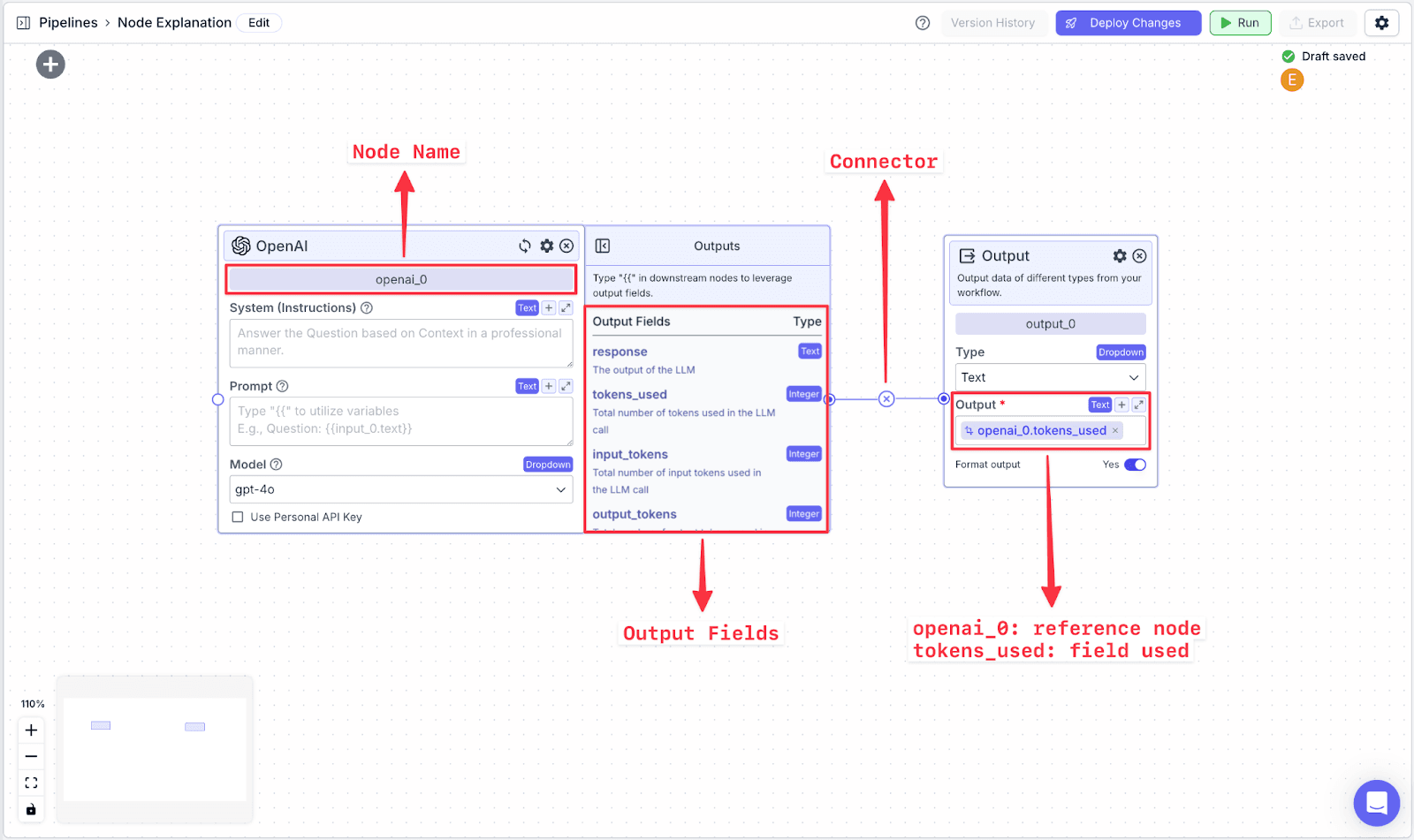
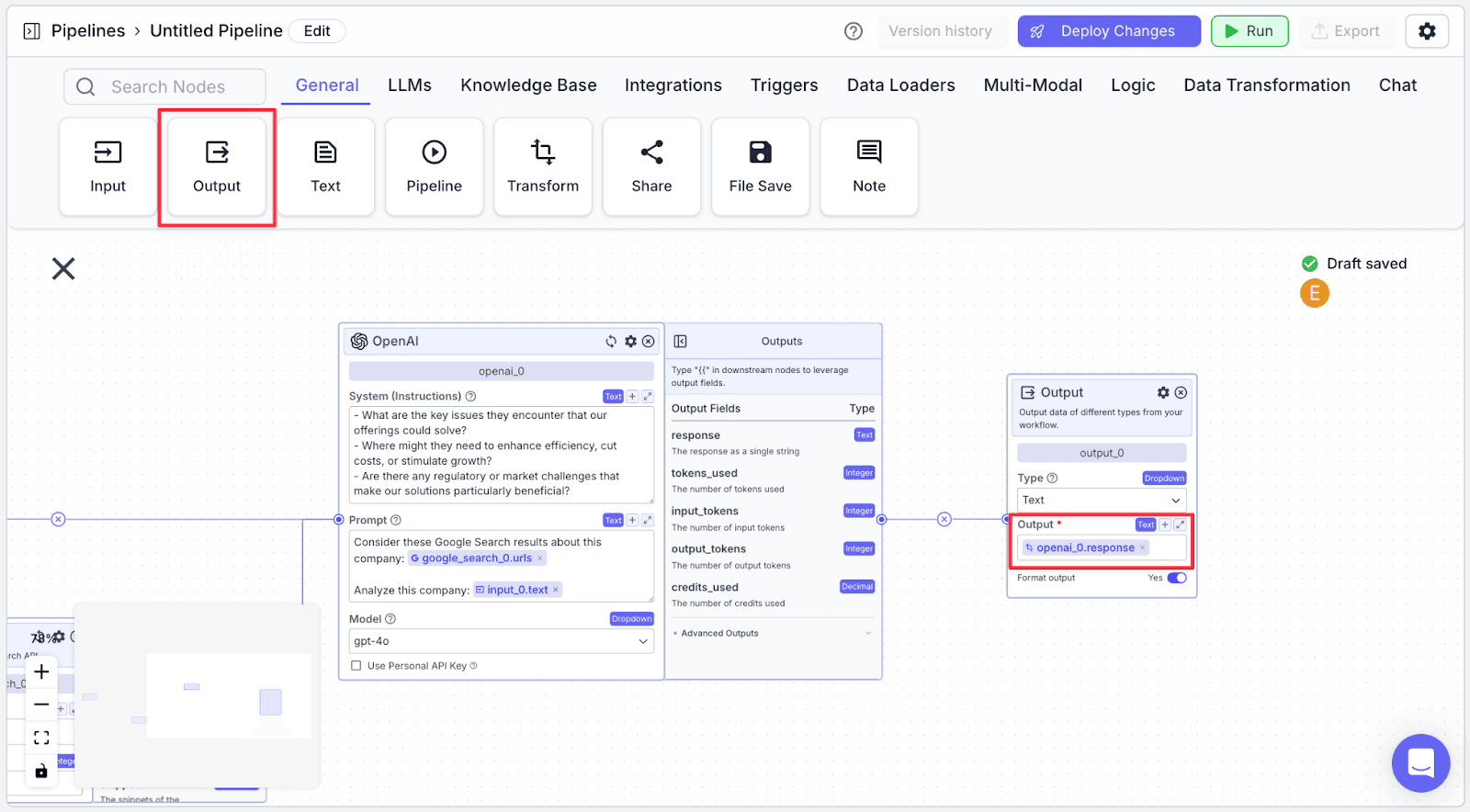
Each node in VectorShift has a name at the top of each node (e.g., openai_0) and output field(s), which are found in the right-hand pane of each node (e.g., the OpenAI LLM node has various output fields: response, tokens.used, input_tokens, output_tokens).
To reference specific data fields from other nodes, you have to do two things:
Connect the two nodes.
Reference the data from the previous field using a variable.
Variables in VectorShift all have the same structure:
You can also create variables by typing “{{“ in any text field, which opens the variable builder. To reference the text from the OpenAI node, you call the variable on the Output node:
To start creating a new pipeline, go to the “Pipeline” menu, and click “New” on the top-right
Click on “Start Blank” on the top right.
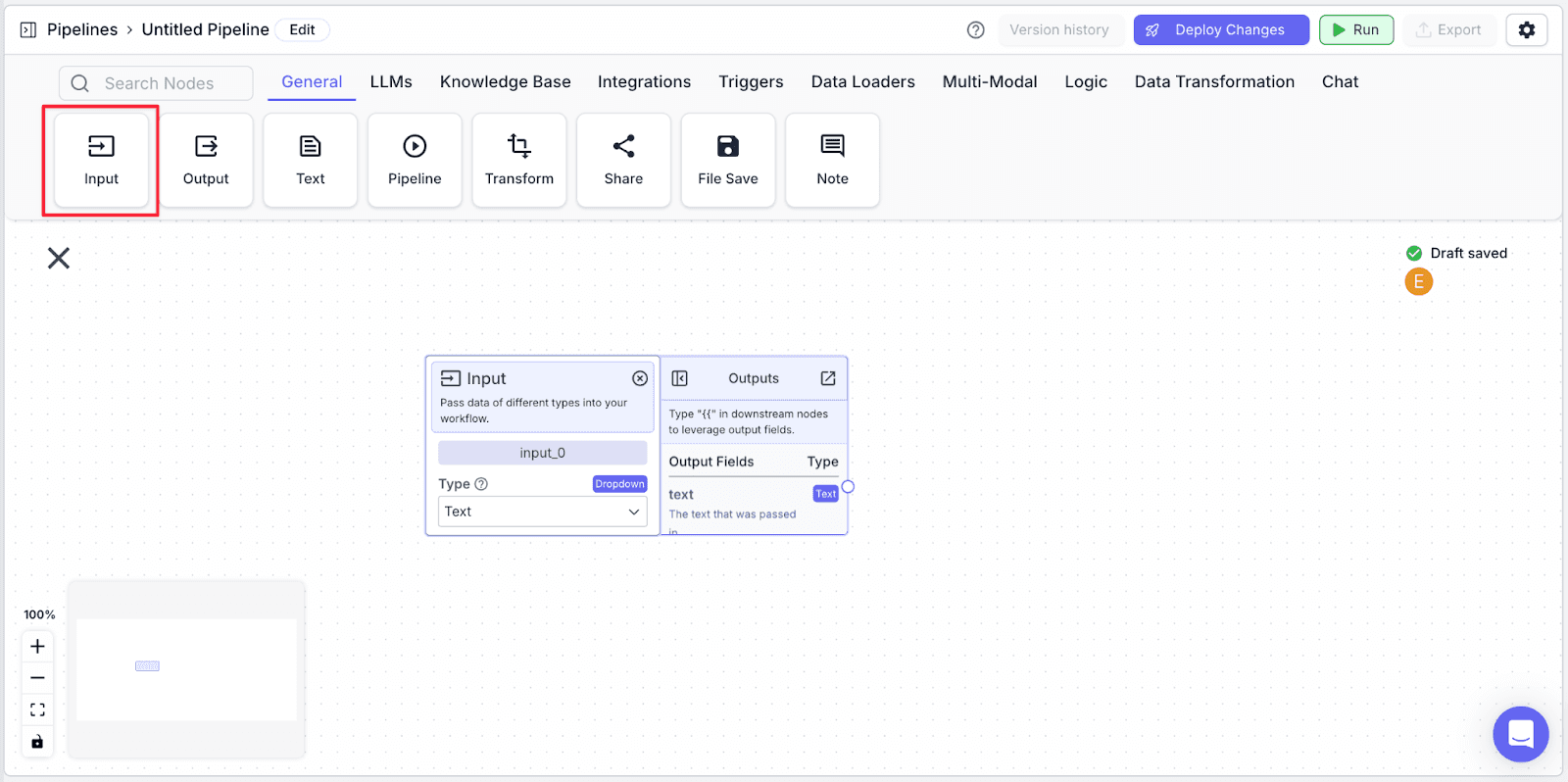
Input Node
From node options under the “General” tab, drag out an “Input“ node. An input node allows data to be inputted into the pipeline (here, the name of the company to score).
Web Search Node
The “Web Search” node allows the pipeline to browse the internet to find relevant data.
Step 1: Take the “Web Search” node under “Data Loaders”. Click on “Google Search” in the “Web Search“ node.
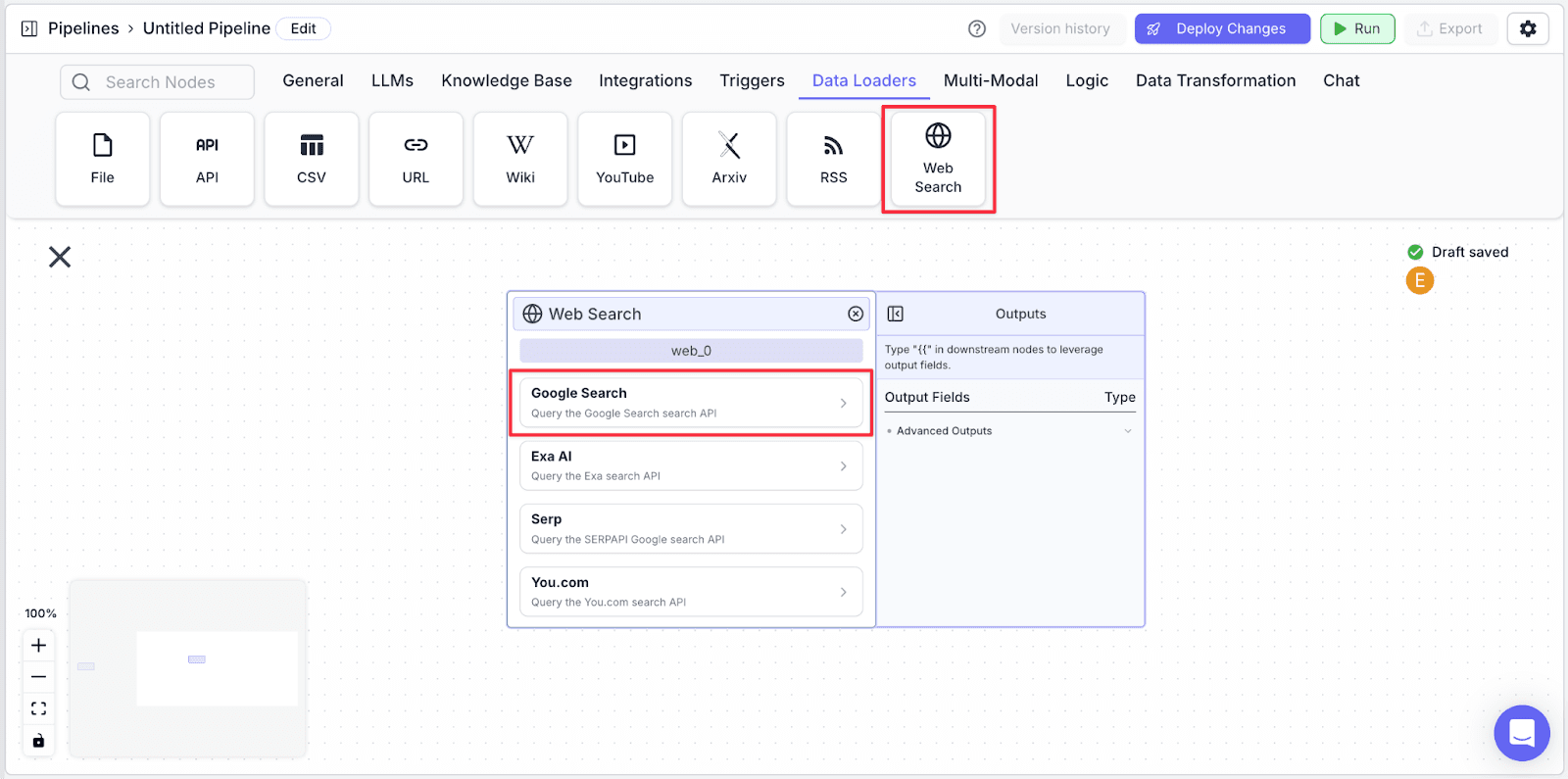
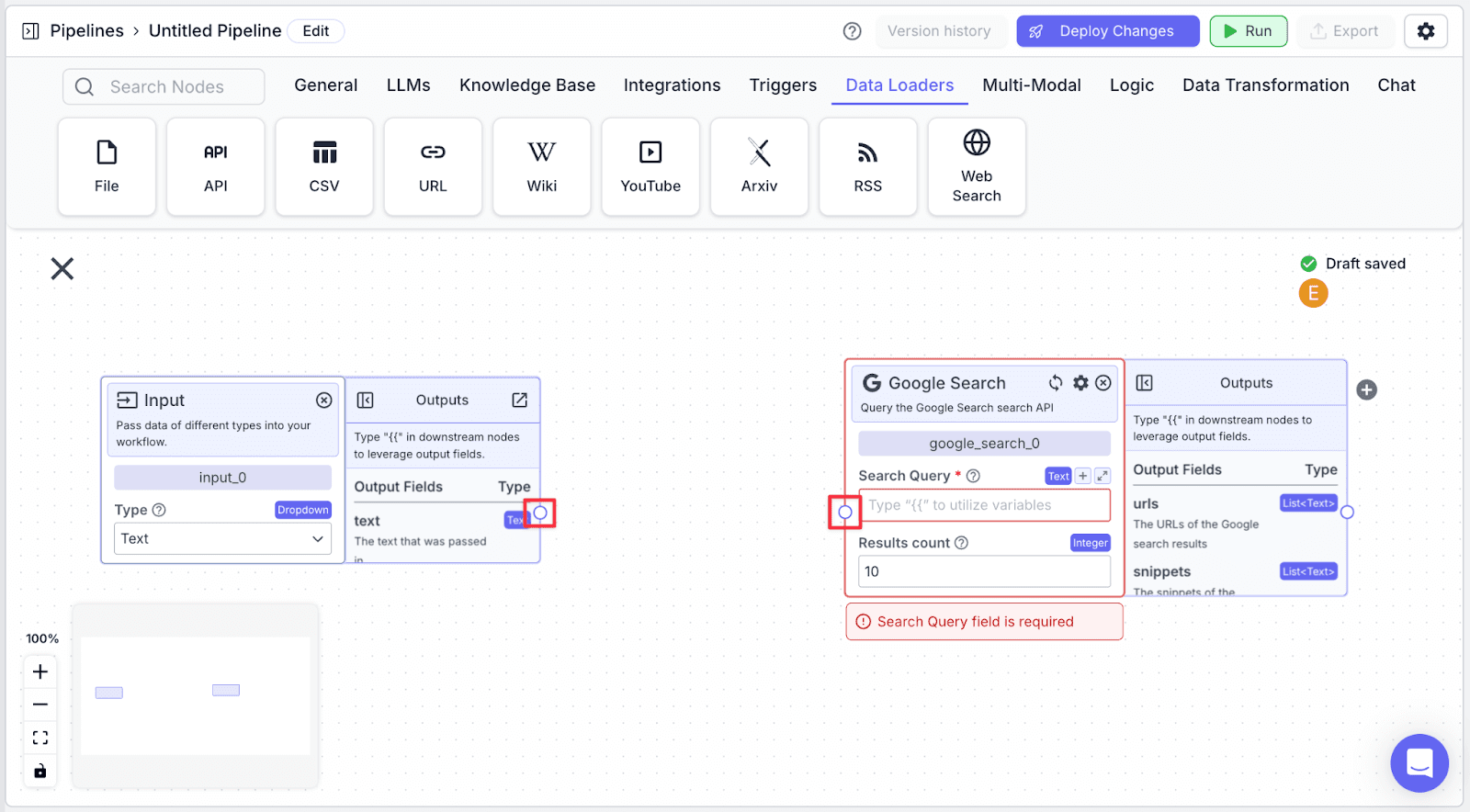
Step 2: Connect the “input_0” node with “google_search_0” by dragging the connector.
The “input_0.text” variable will be automatically populated into the “Search Query” field.
LLM Node
We will utilize a LLM node to summarize data about a potential lead from the Google search.
Step 1: Take an “OpenAI” node under the “LLMs” tab.
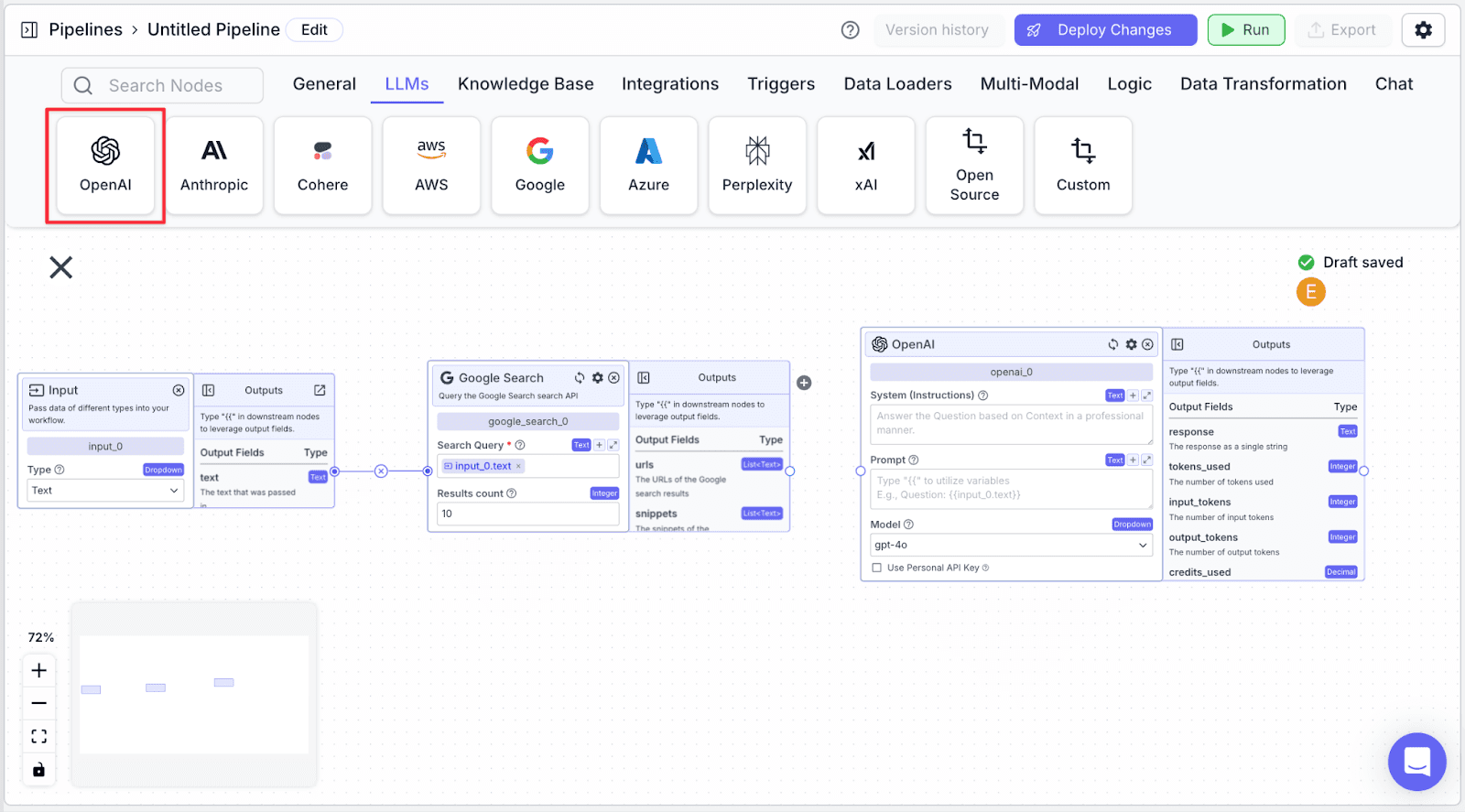
Step 2: Connect the “openai_0” node with “input_0” and “google_search_0”
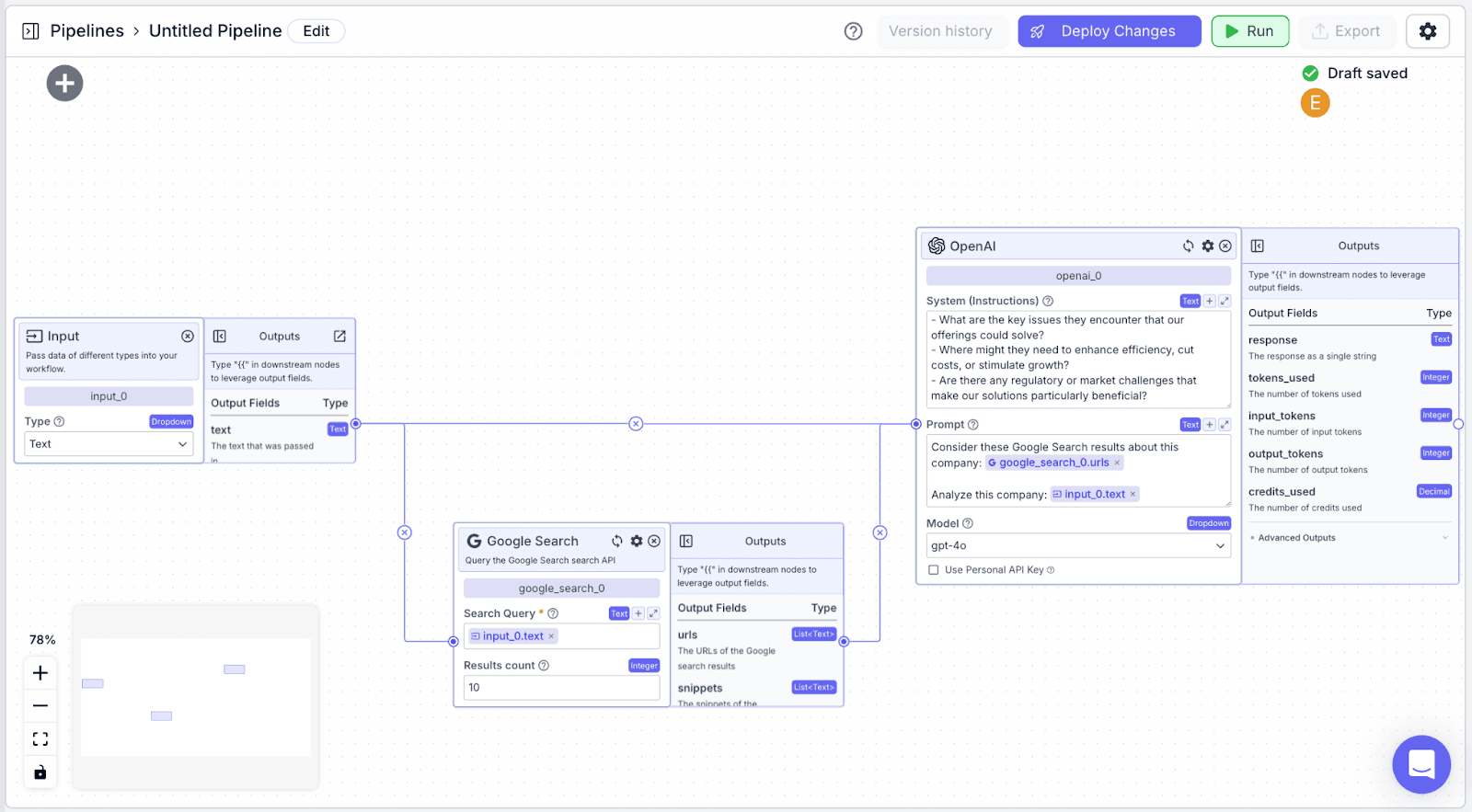
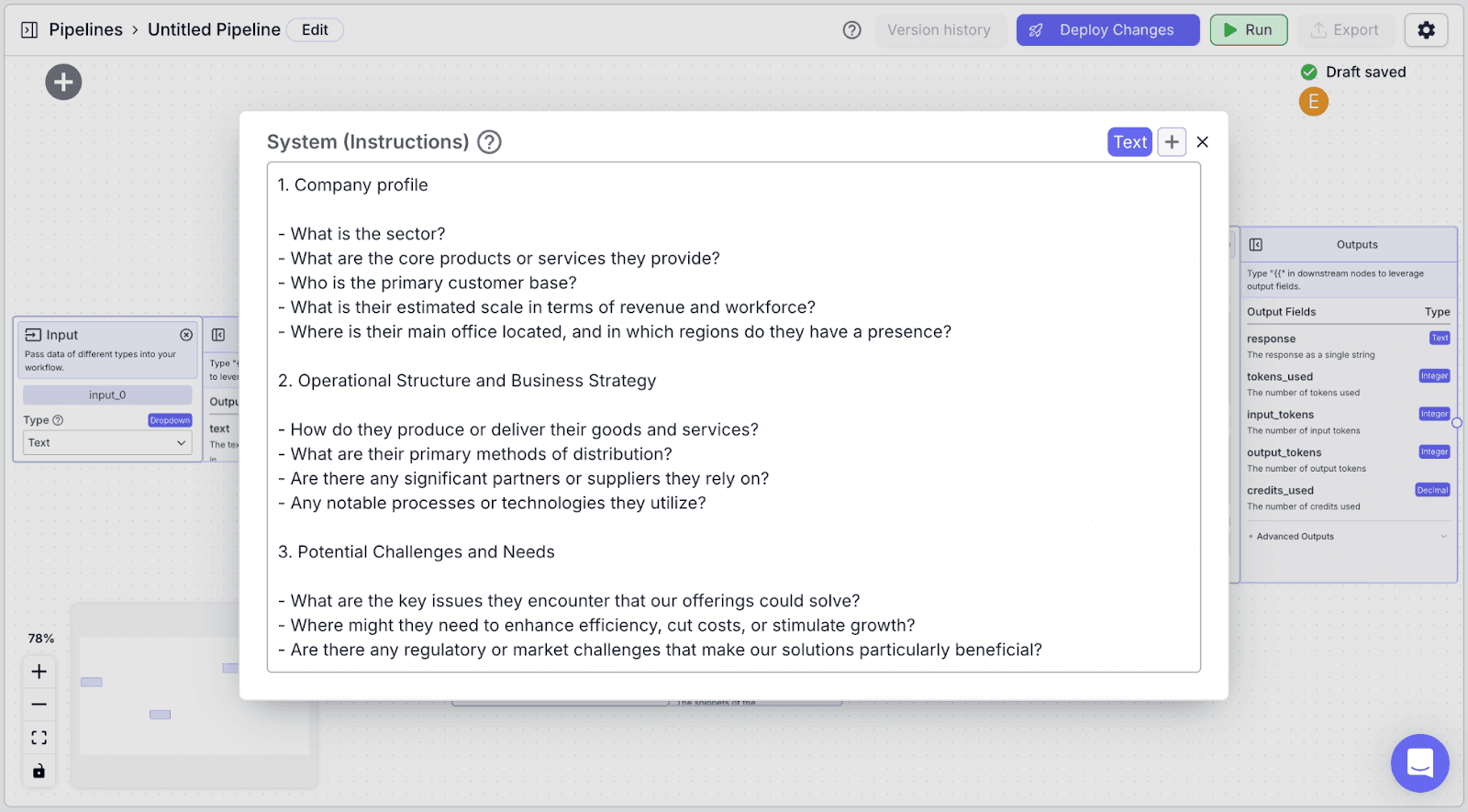
Step 3: The LLM node has two fields: “System (Instructions)” and “Prompt”.
“System (Instructions)” defines how you want the LLM to behave. You can use the instructions below:
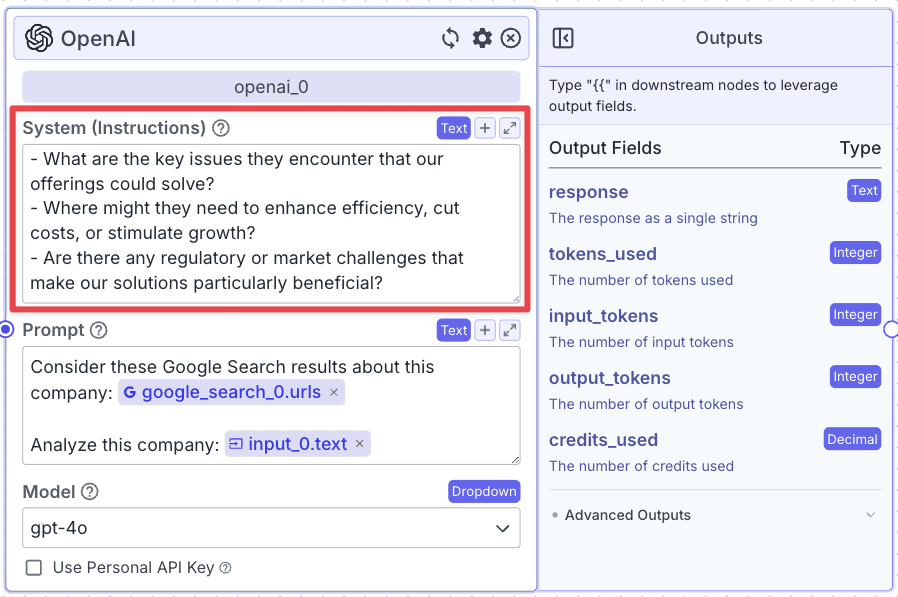
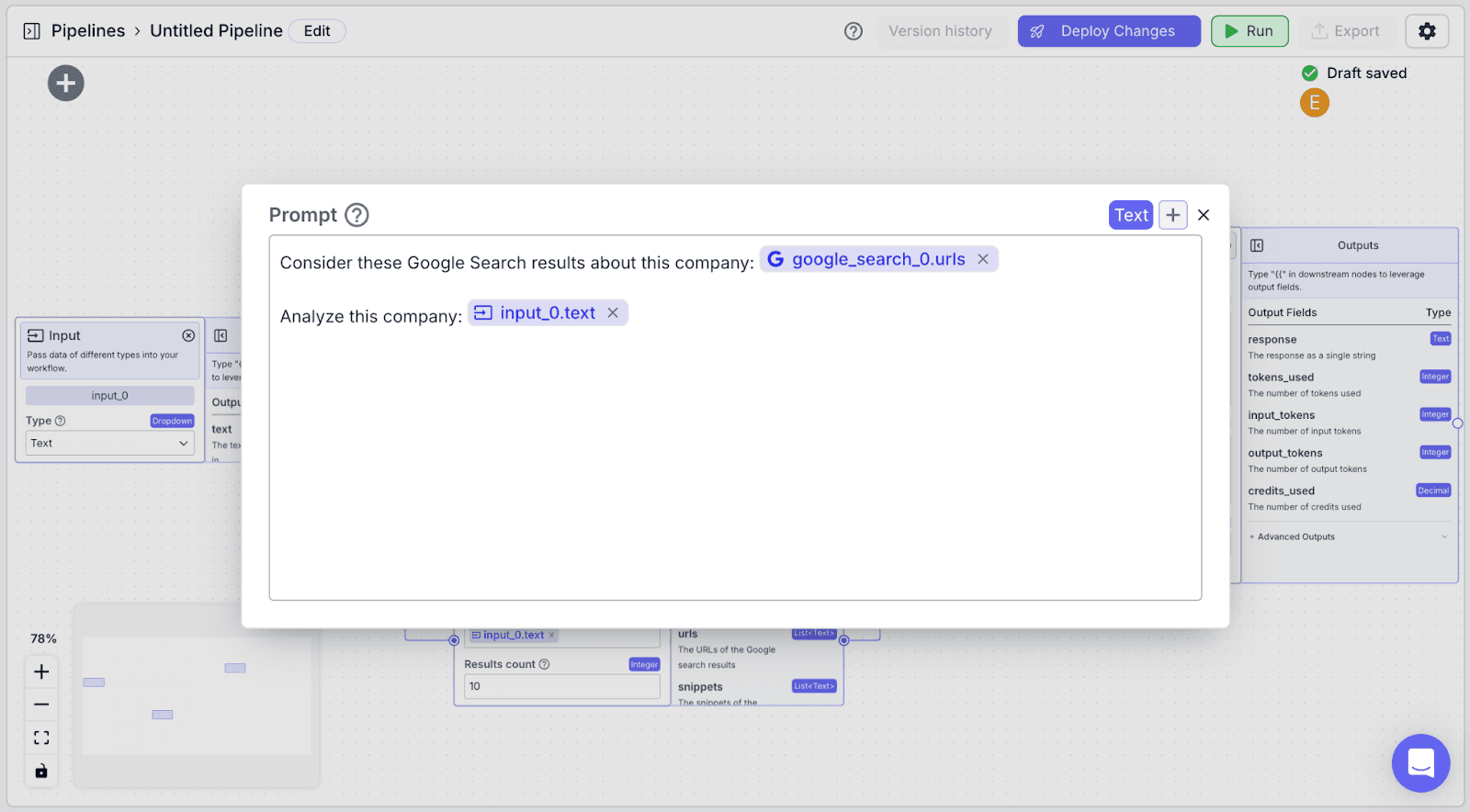
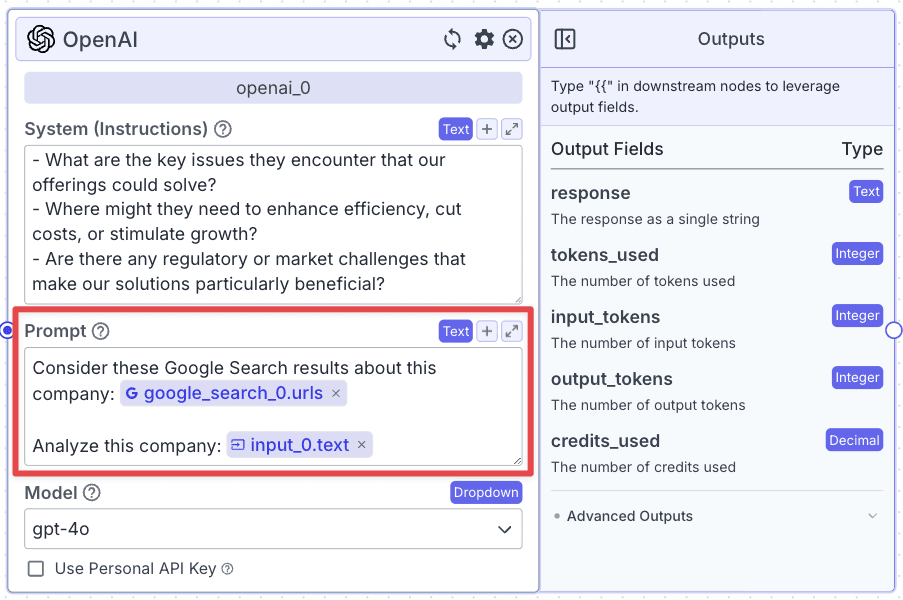
Within the “Prompt”, pass data you want the LLM to use to accomplish its task.
Output Node
Connect the LLM not to an output node. This will display the report generated by the LLM to the user.
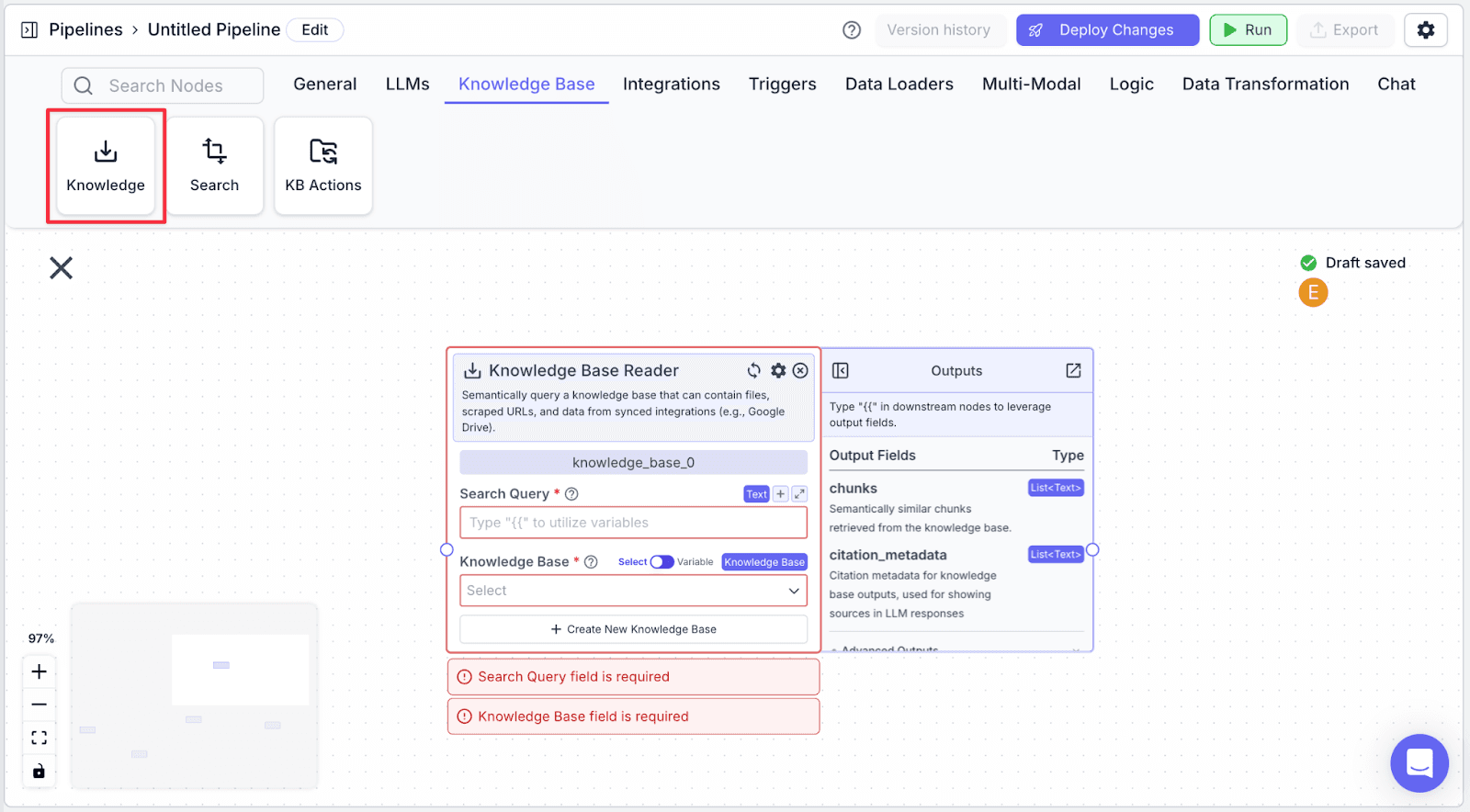
Knowledge Base Node
The knowledge base allows the pipeline access data stored in the knowledge base.
Step 1: Take a Knowledge node under the “Knowledge Base” tab.
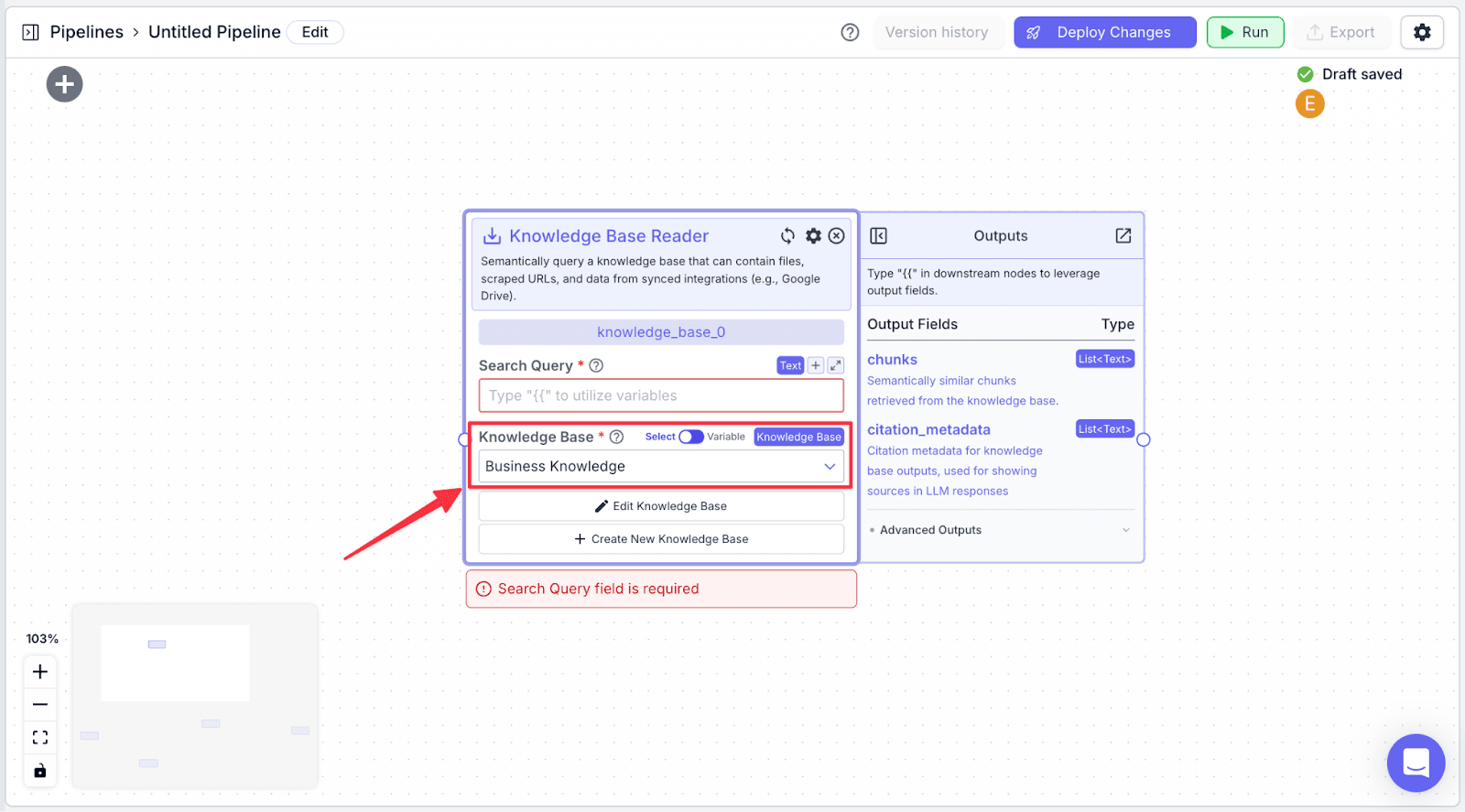
Step 2: Under “Knowledge Base”, choose the knowledge base that was set up in step 1.
Step 3: Connect “input_0” to “knowledge_base_0”.
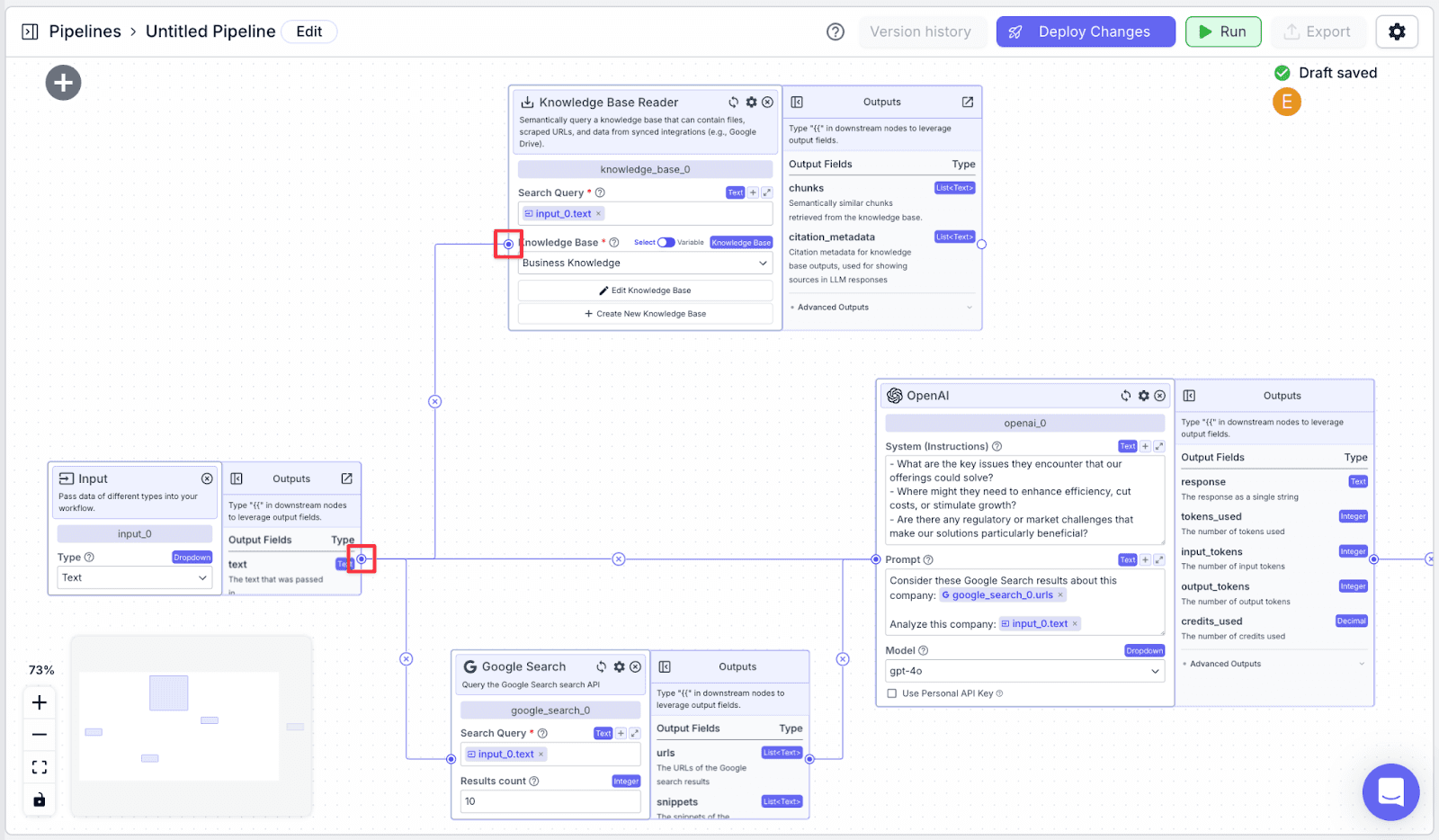
Second LLM Node
Add another LLM and connect with both the knowledge base and the first LLM: “knowledge_base_0” and “openai_0”. This LLM will score the customer based on 1) the customer report generated by the first LLM and 2) data from the knowledge base.
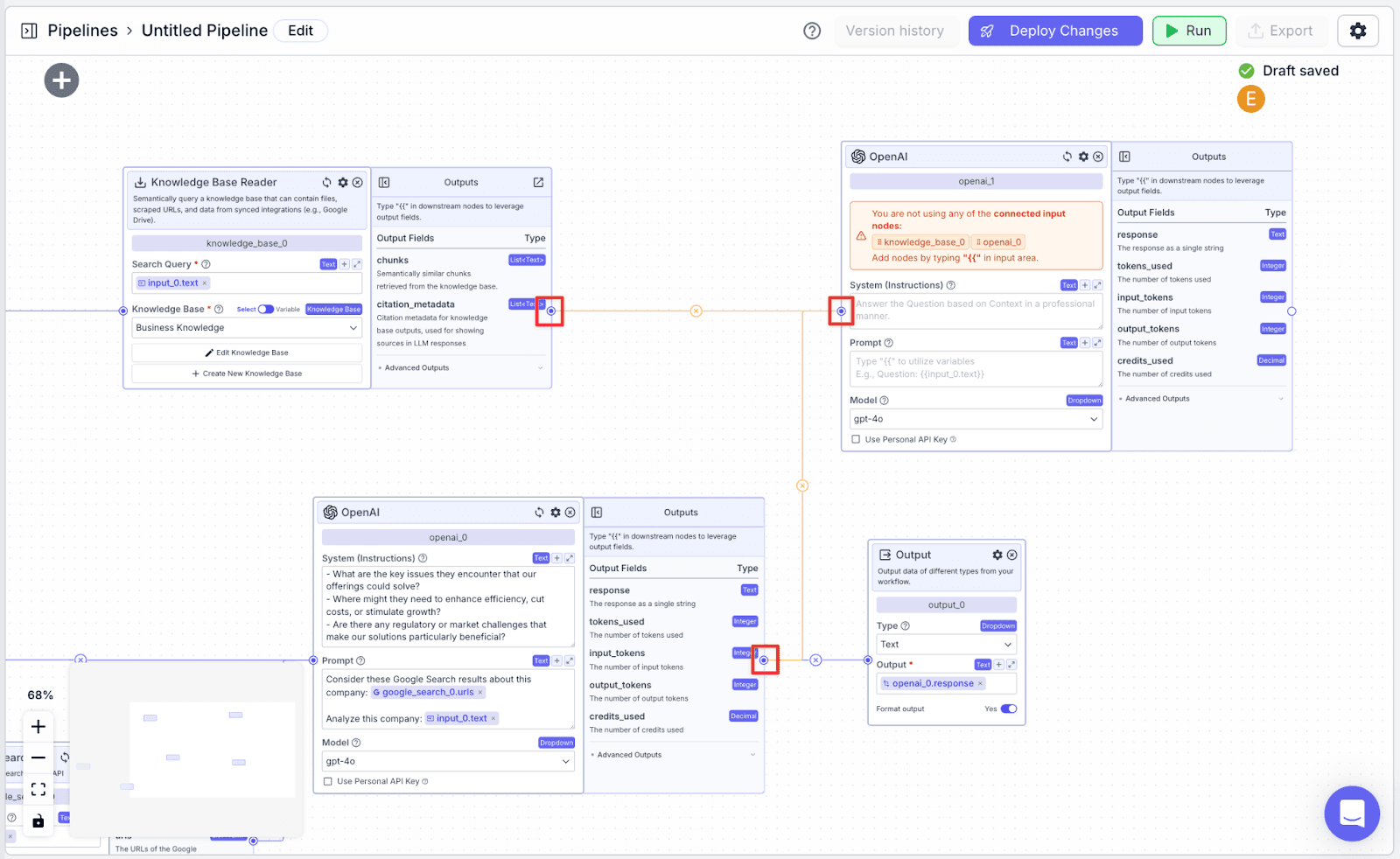
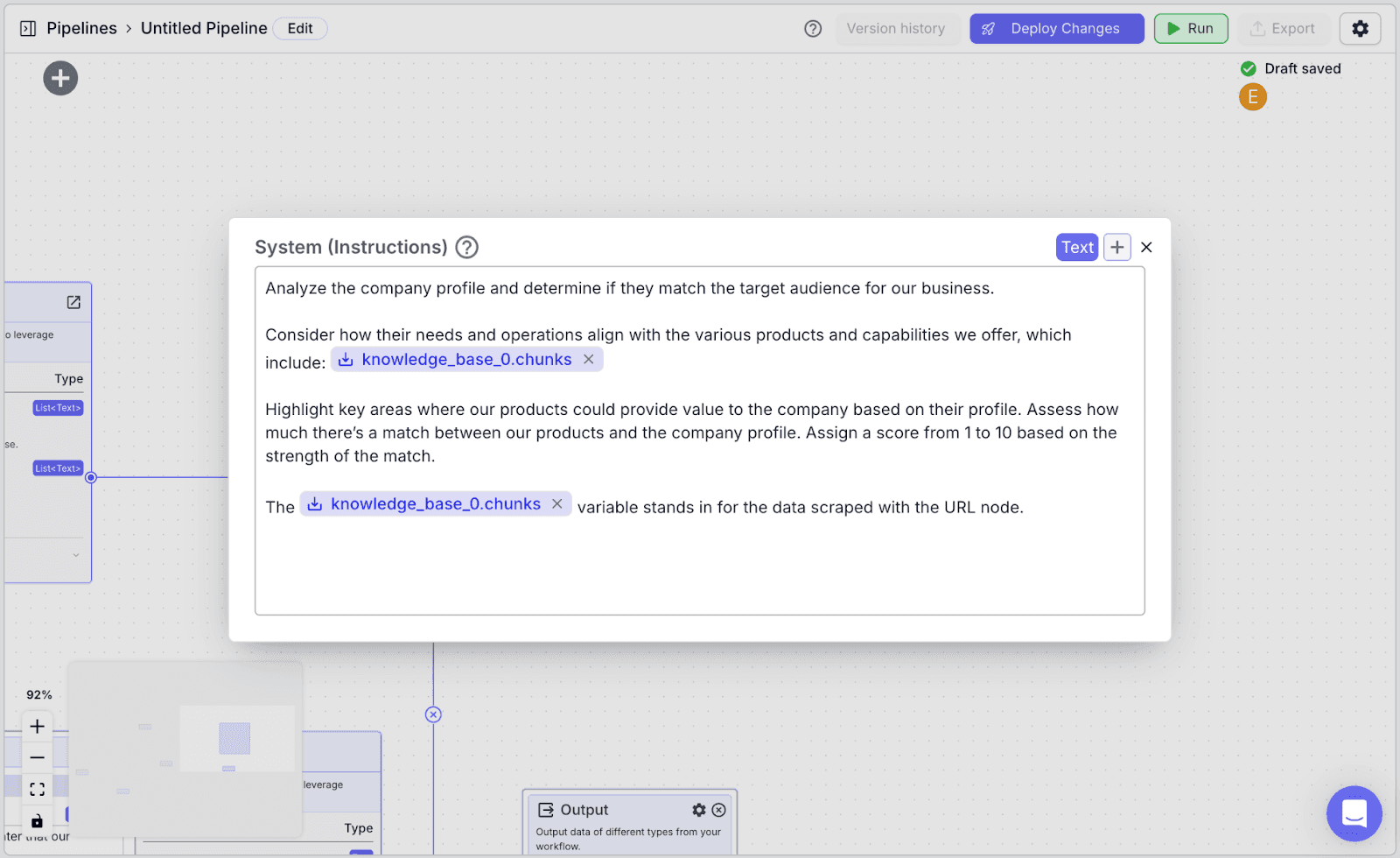
Use the System Prompt for the second LLM node.
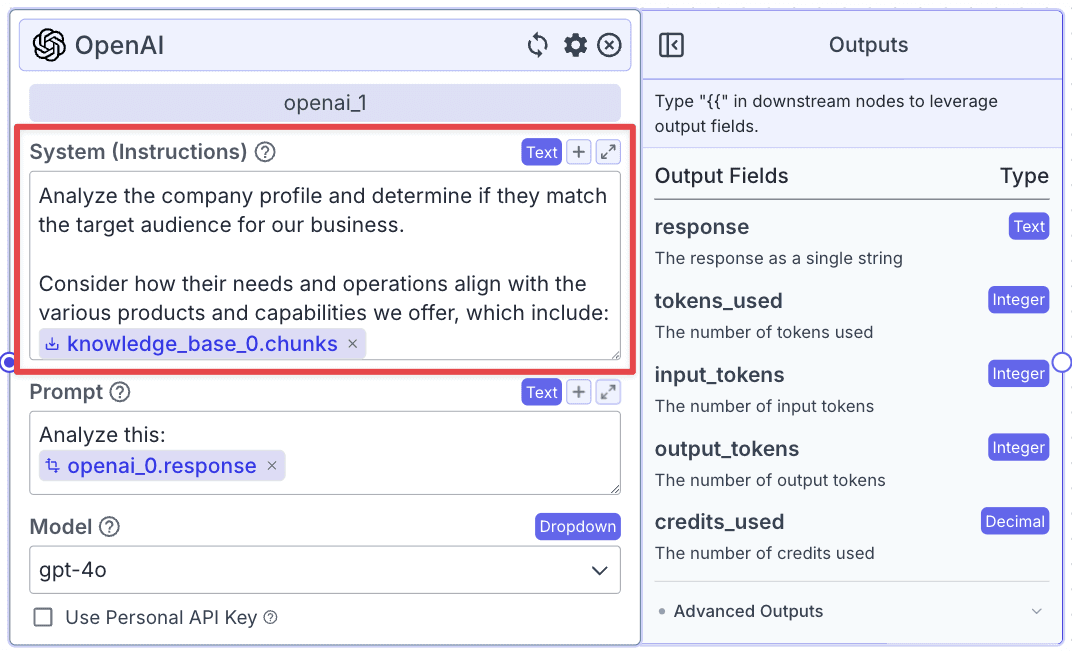
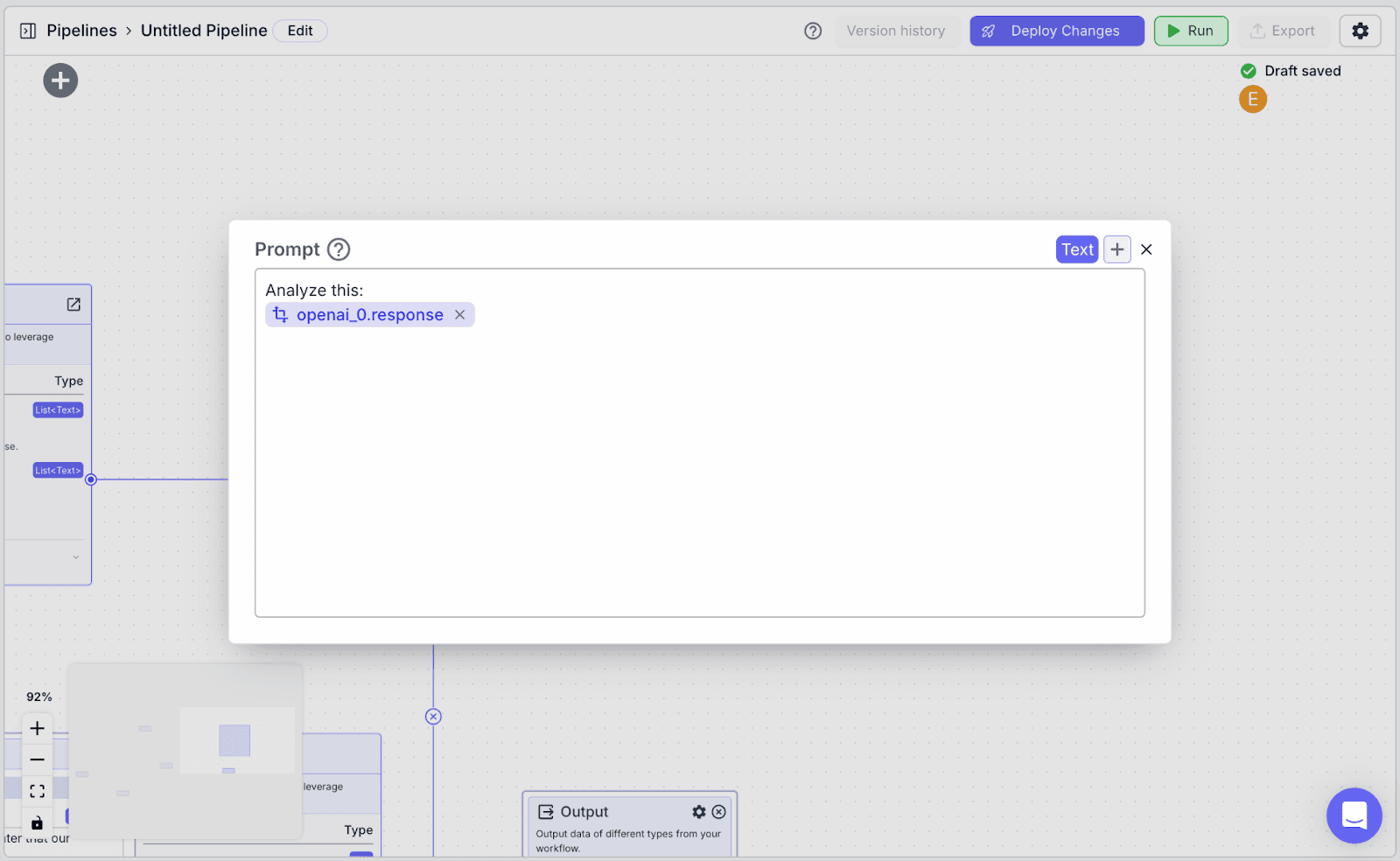
Use this Prompt template for the second LLM node.
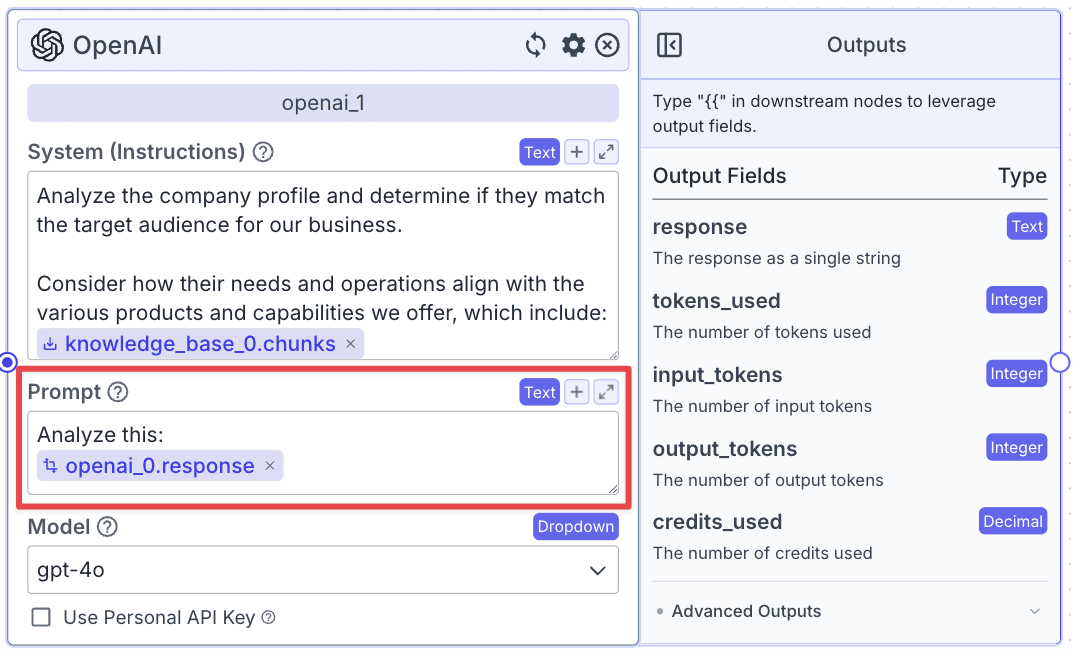
Add Another Output Node
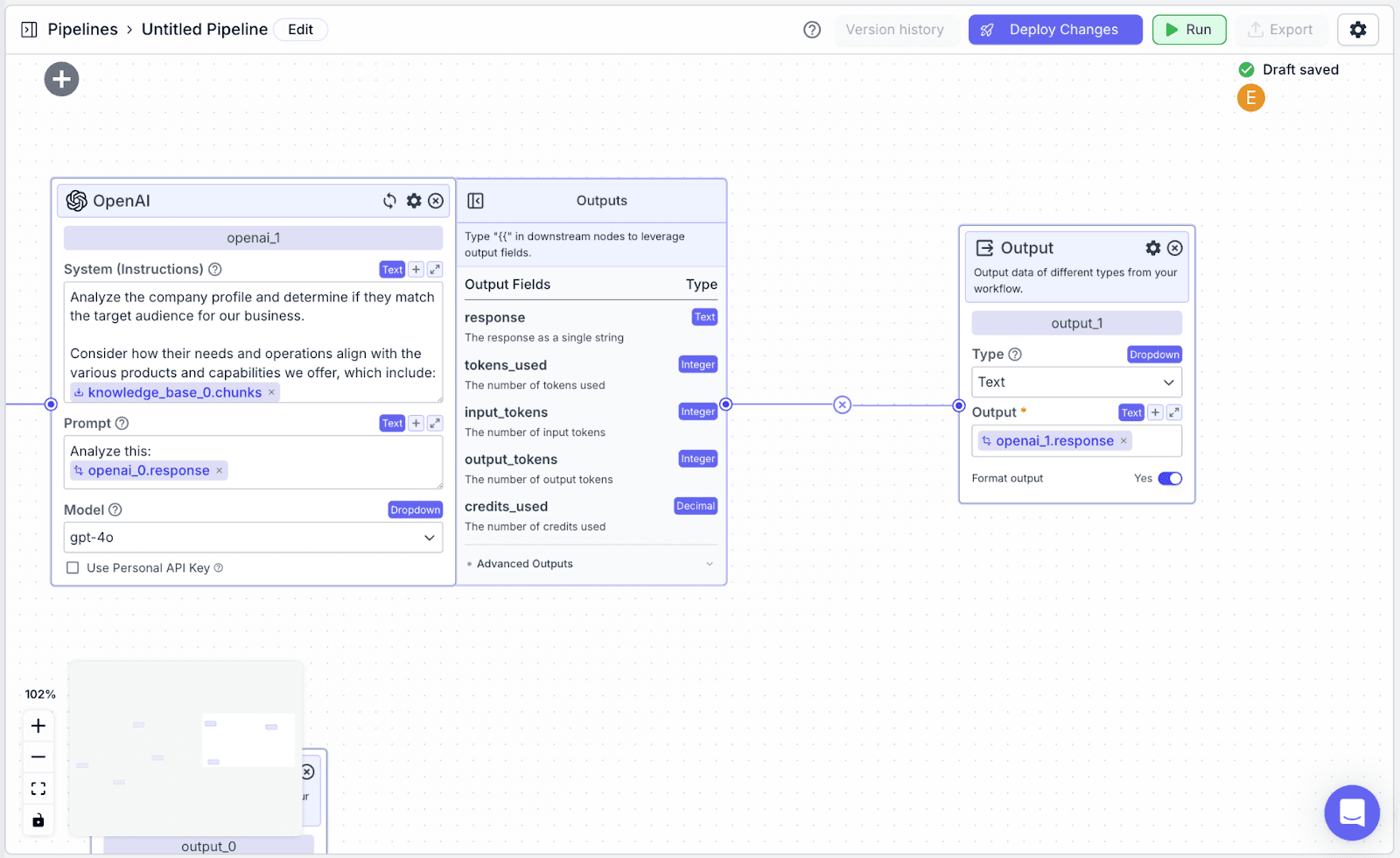
Add another Output node (“output_1”) and connect it with the “openai_1” node. This will display the lead score to the user.
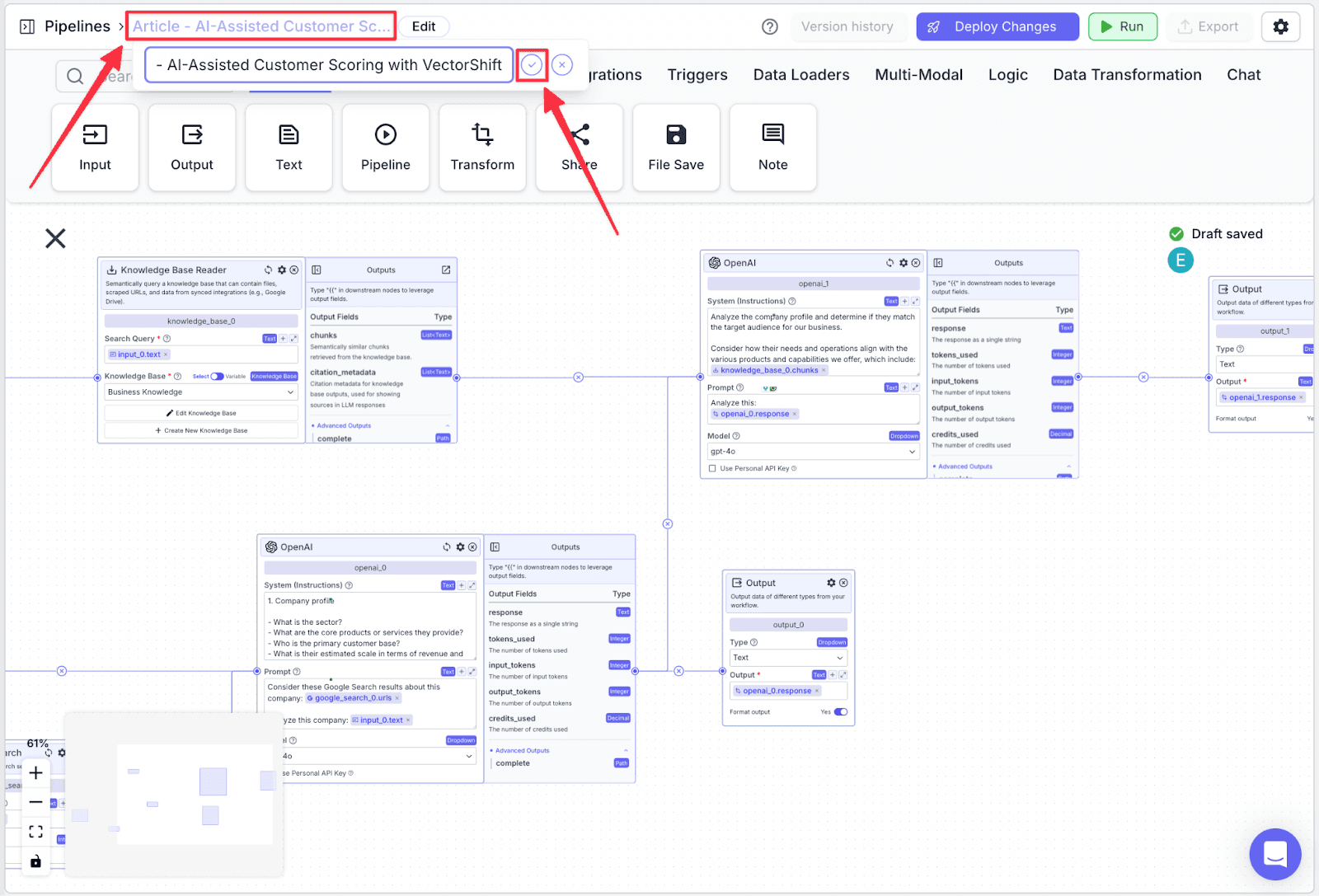
Renaming the Pipeline
To rename the pipeline, click the pipeline name in the top-left part, then click on the check icon to apply the new name.
Running the Pipeline
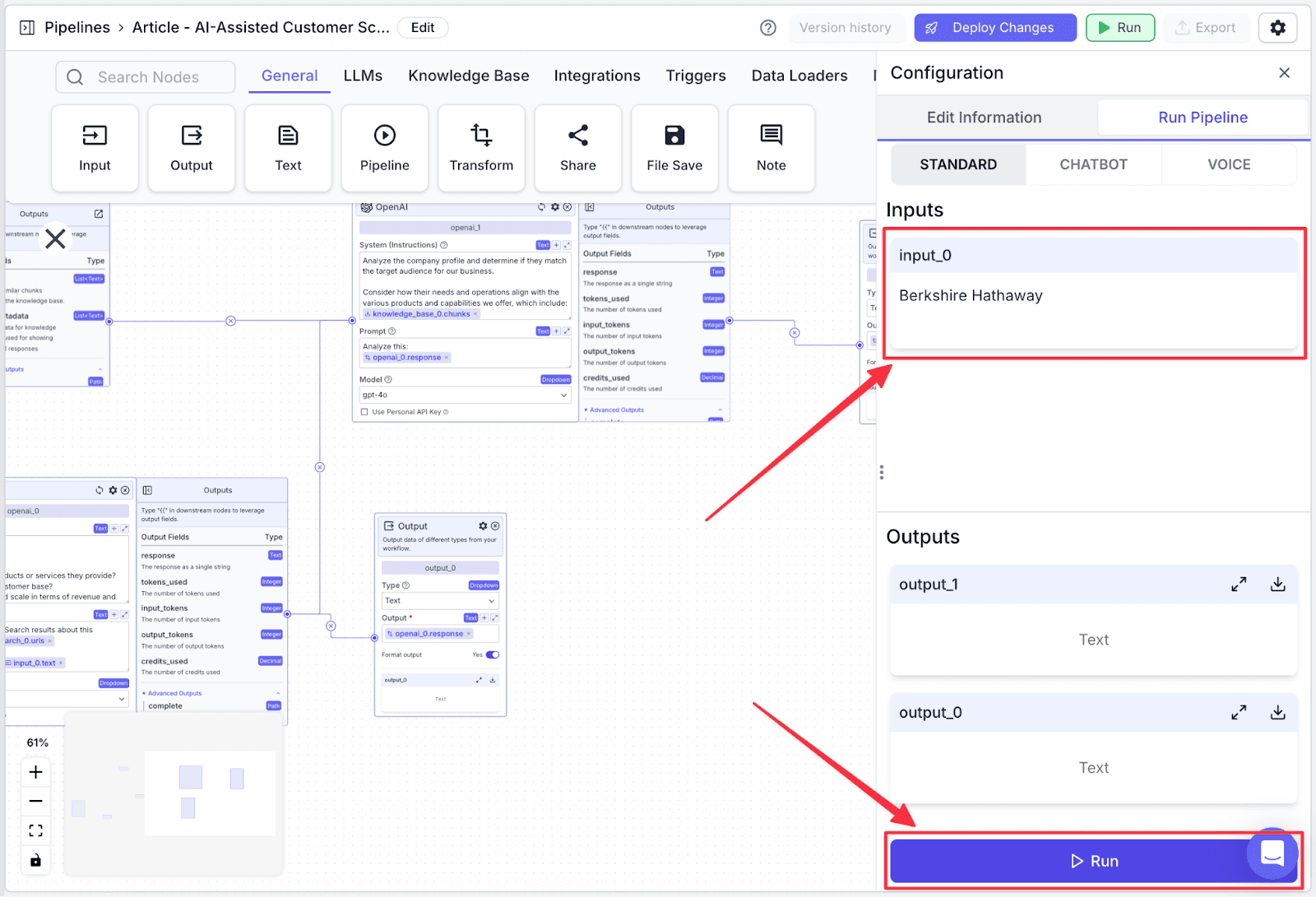
Click “Run” on the top-right of the window. You will show the “Run Pipeline” pane on the right part of the screen.
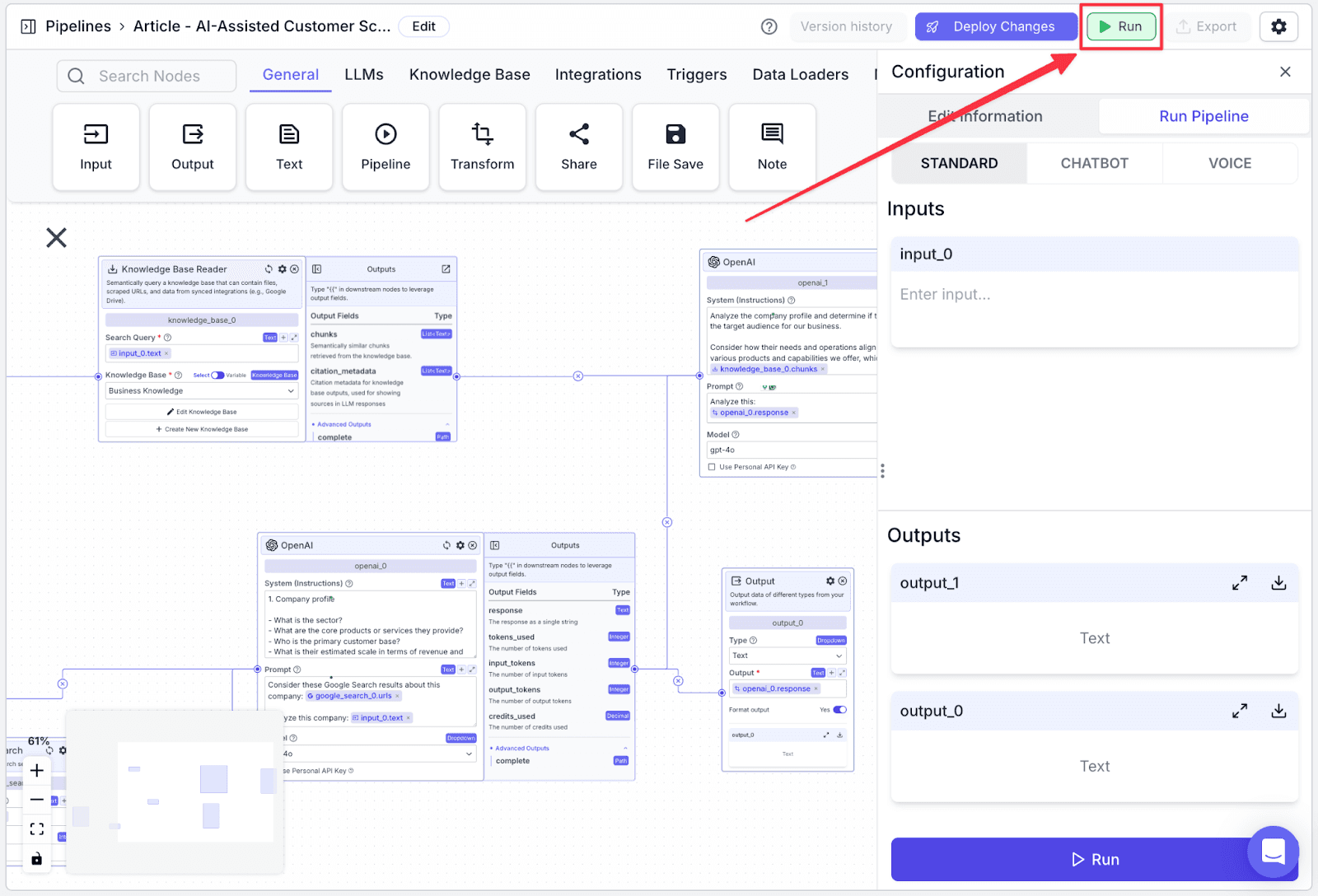
Write any company name you wish to check in “input_0”, then click the “Run” button at the bottom.
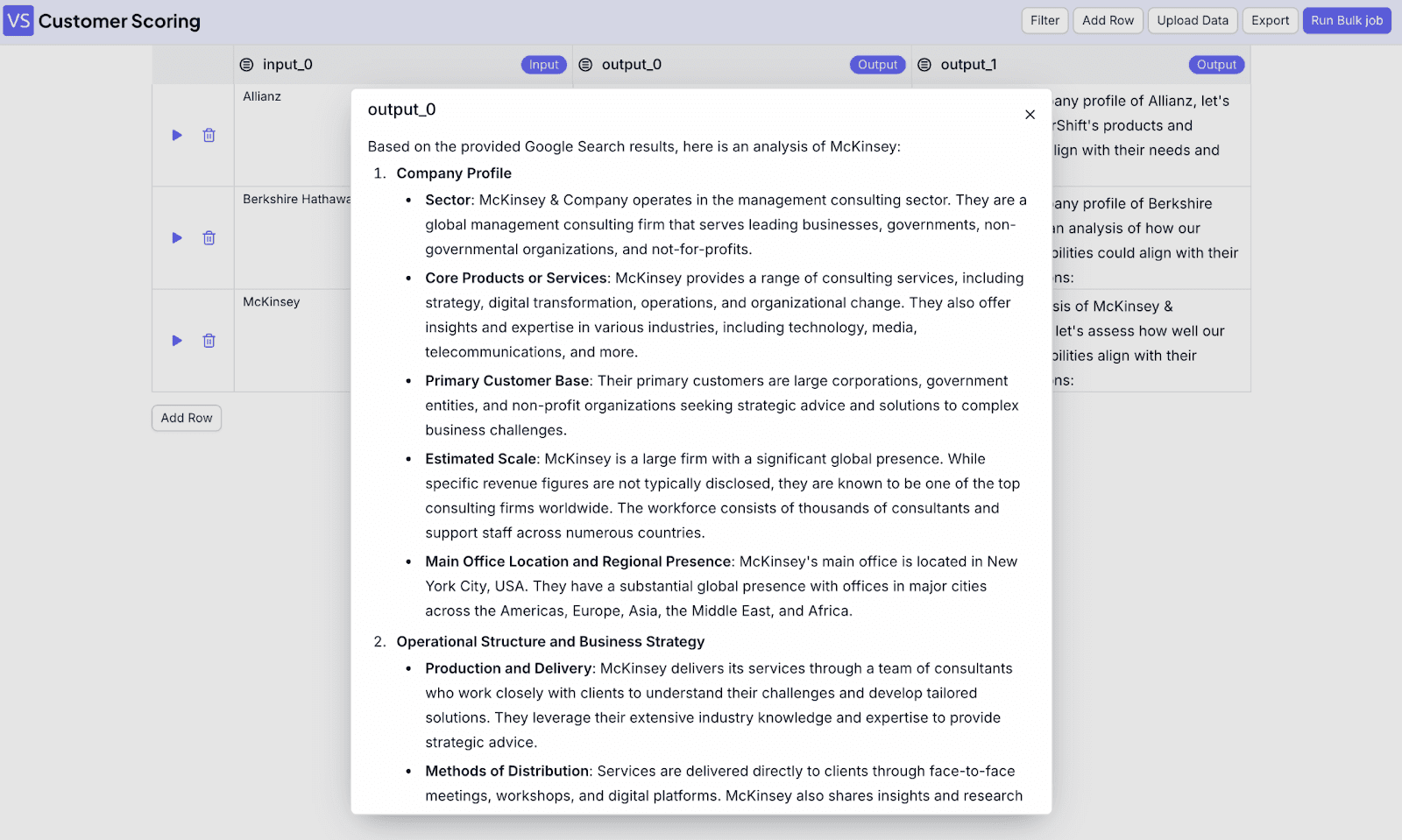
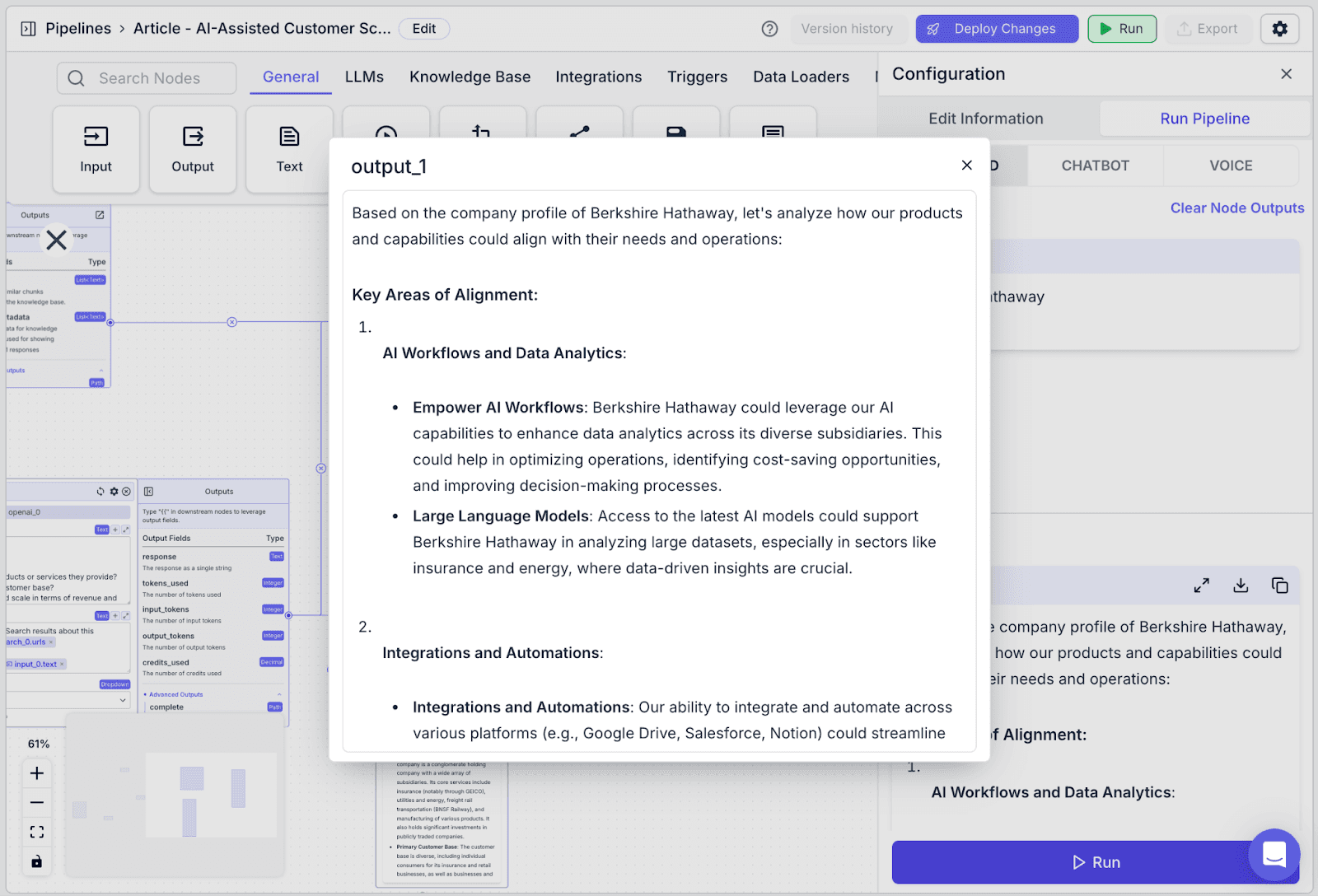
Here is example output output:
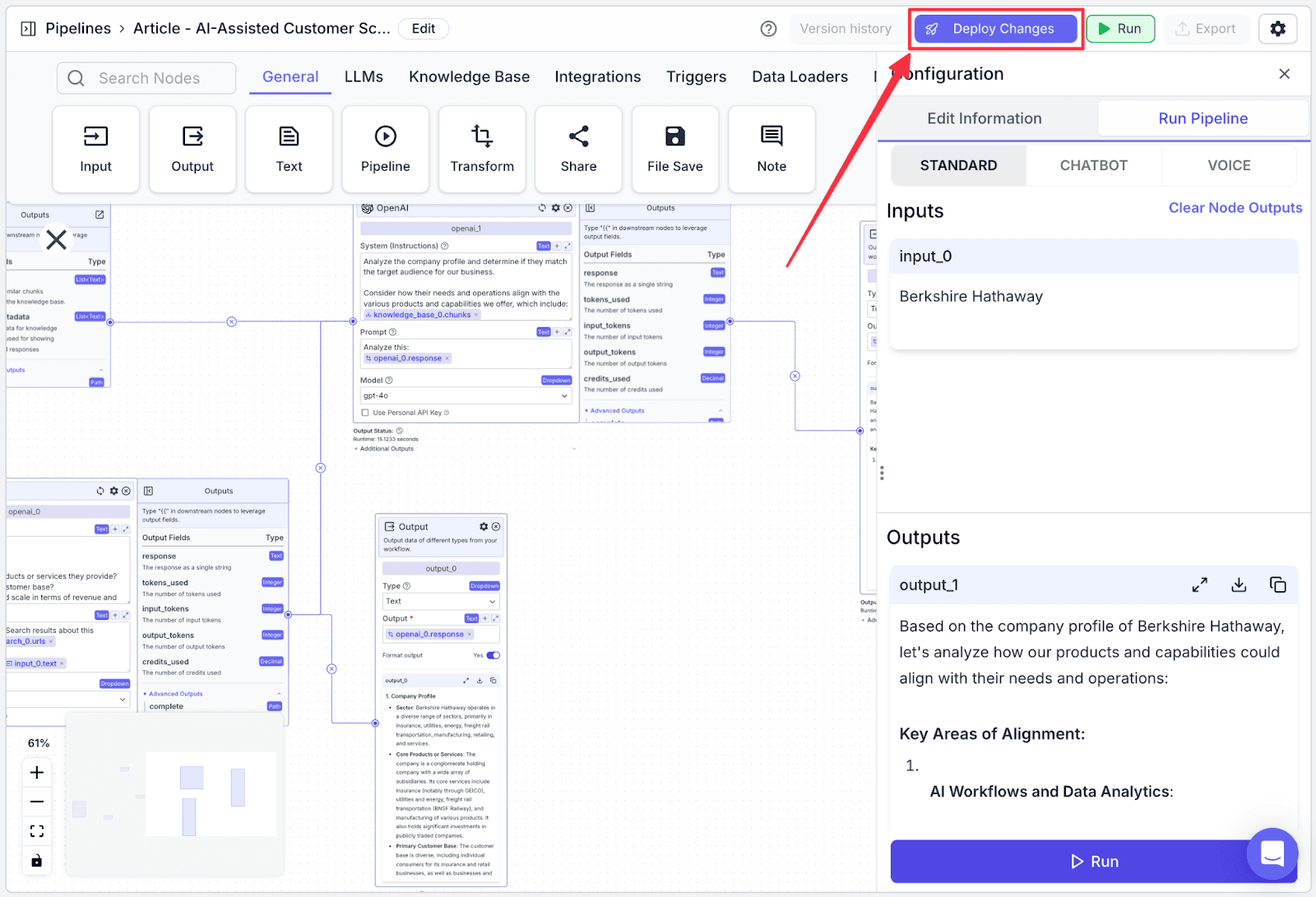
Deploying the Pipeline
The last thing you need to do is to deploy the pipeline. This allows you to track your pipeline versioning in case you want to revert to the previous version. Click “Deploy Changes” to continue.
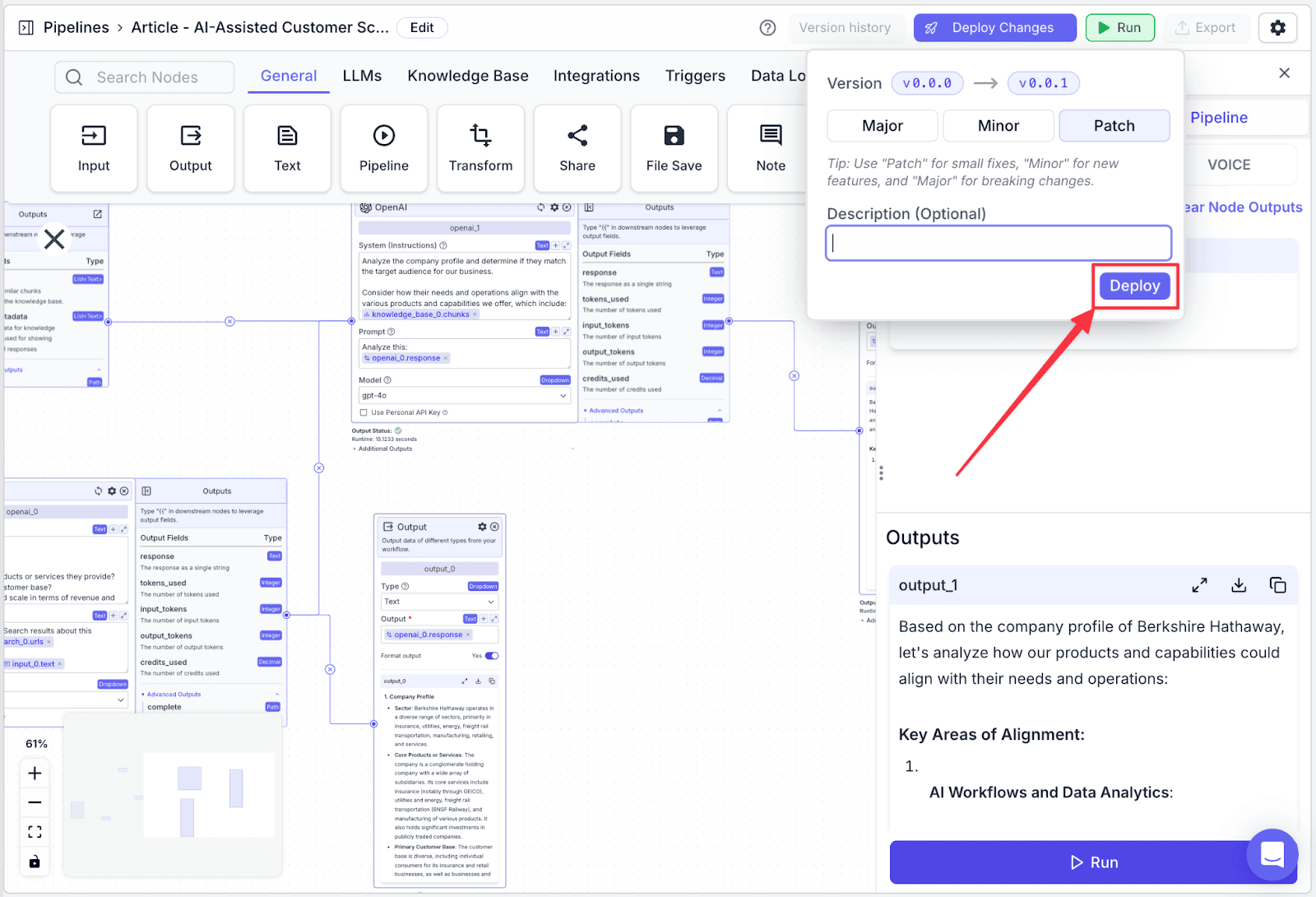
In the deployment interface, you will be given the option to add a “Description (Optional)” to your deployment and its version. This helps you to track what changes each version. Click on the “Deploy” button to apply the changes.
3. Exporting the Pipeline
Exporting the pipeline allows the pipeline to be easily used by end-users (e.g., sales reps).
Step 1: Click on the “Export” on the top right.
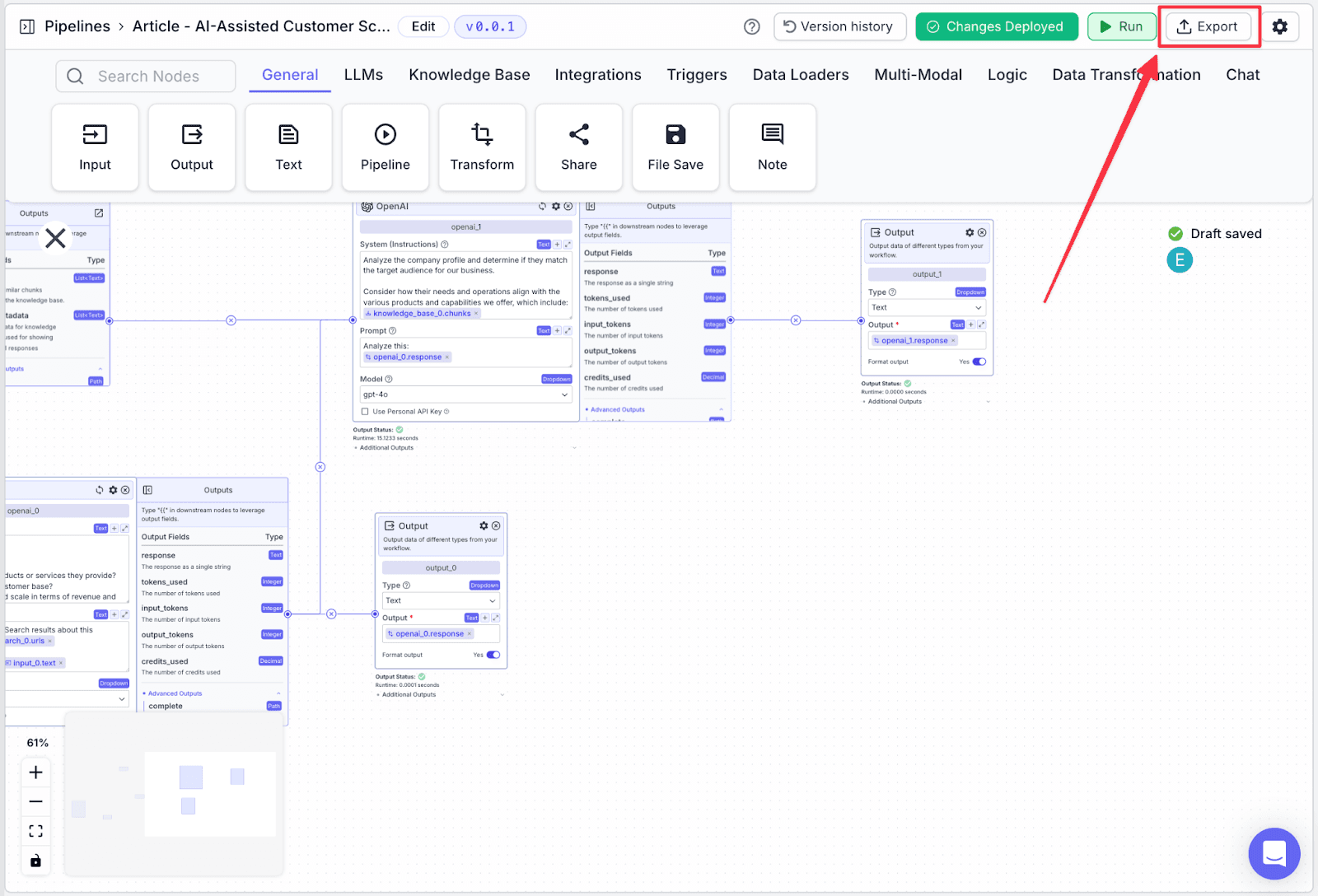
Step 2: You will see some options to export your pipeline. For this article, click on “Bulk Jobs”.
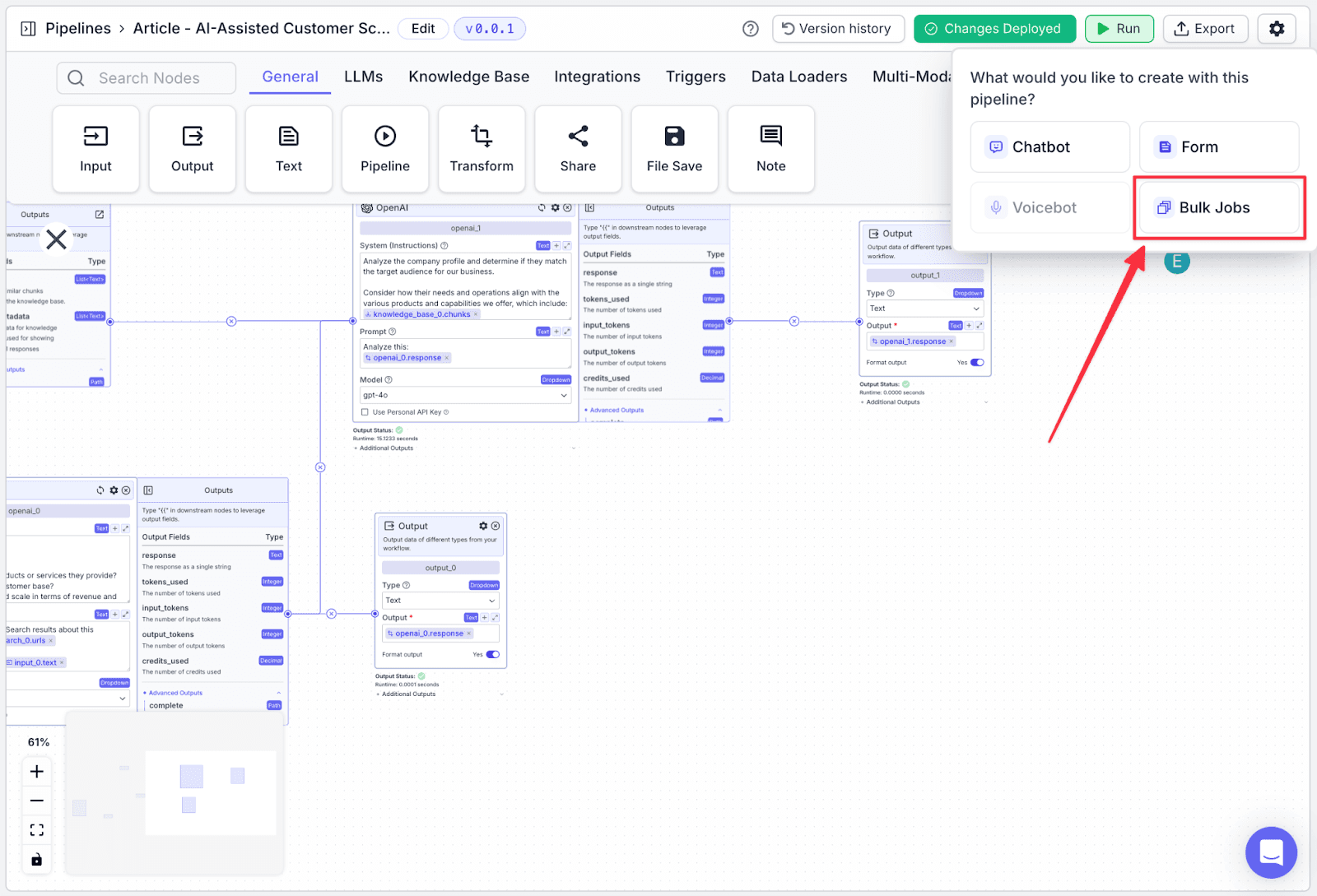
Step 3: Give a name to the bulk job name then click “Create Bulk Job”.
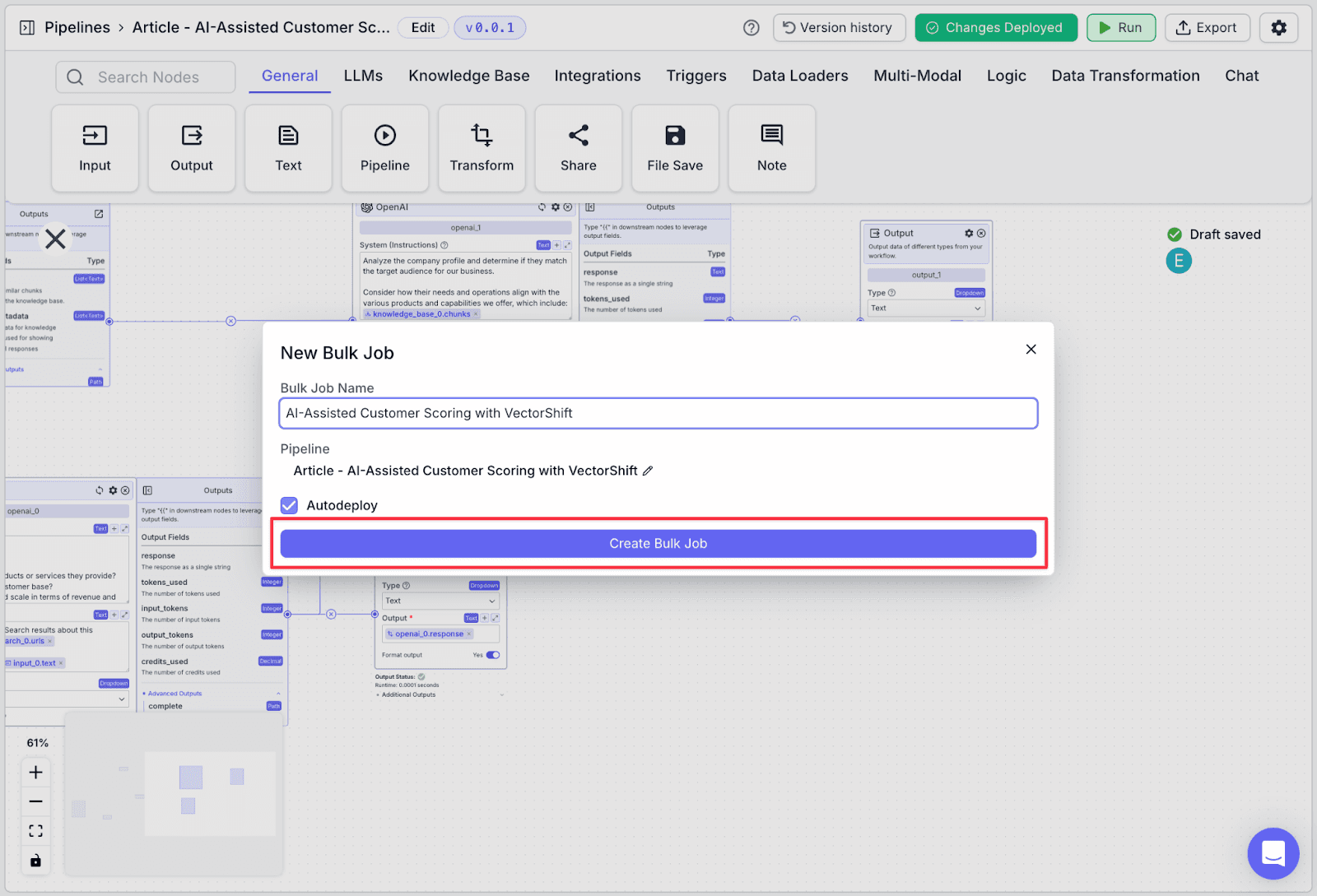
Step 4: Make any necessary changes on the left pane. For example, change the title to “Customer Scoring”. Then click on “Deploy Changes”.
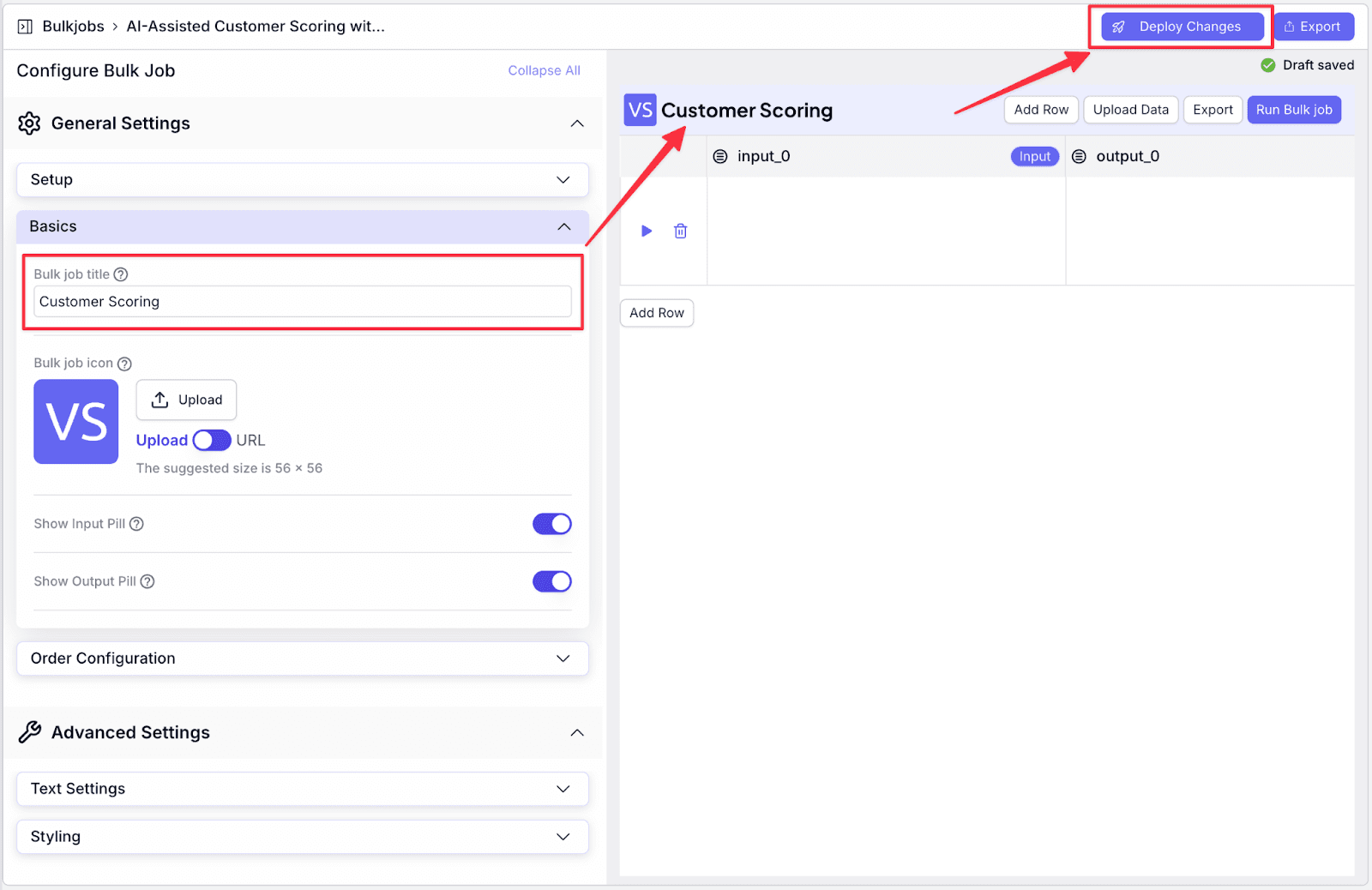
Step 5: Click “Deploy” again.
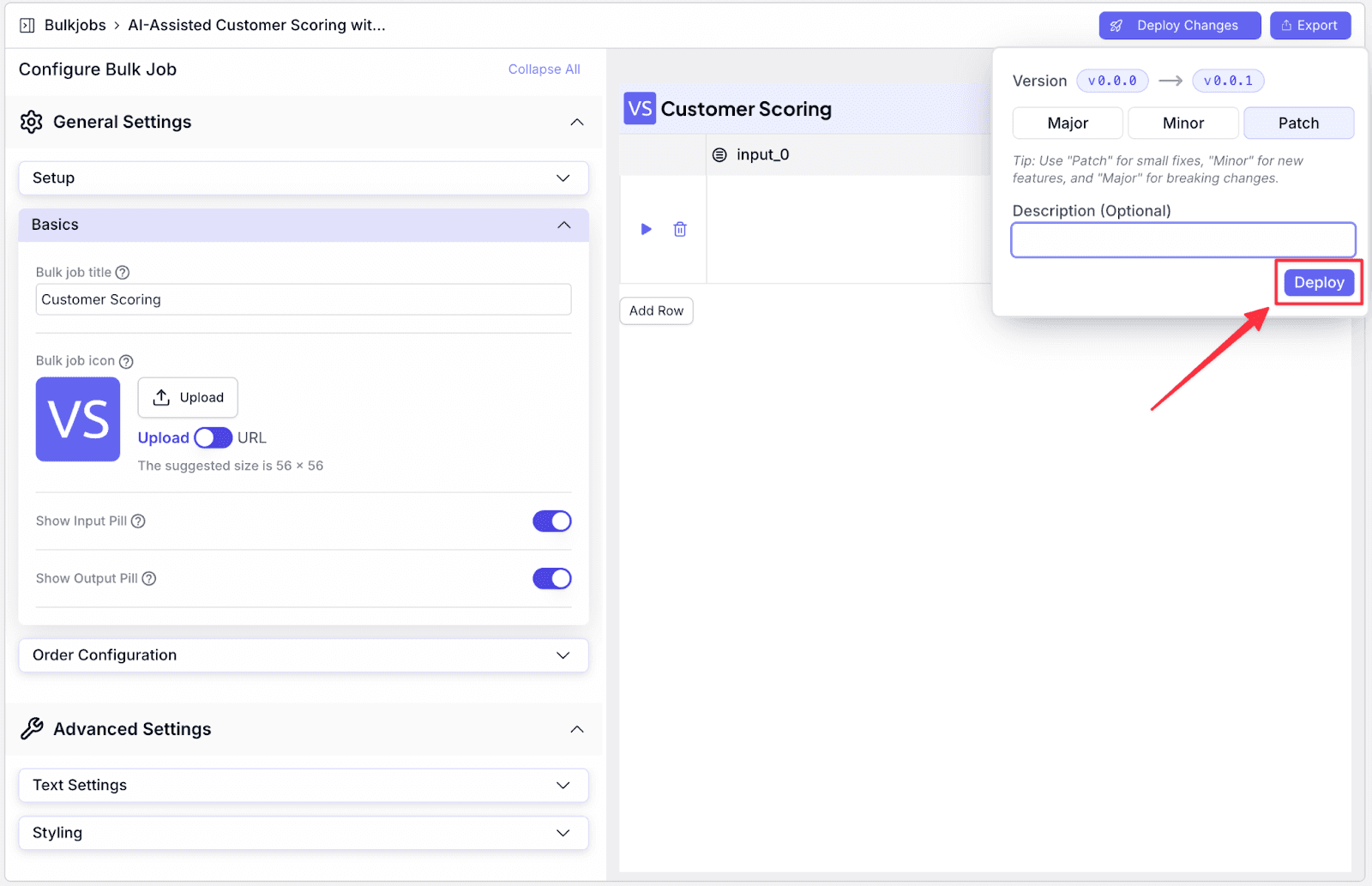
Step 6: After deploying the latest update, click on “Export”.
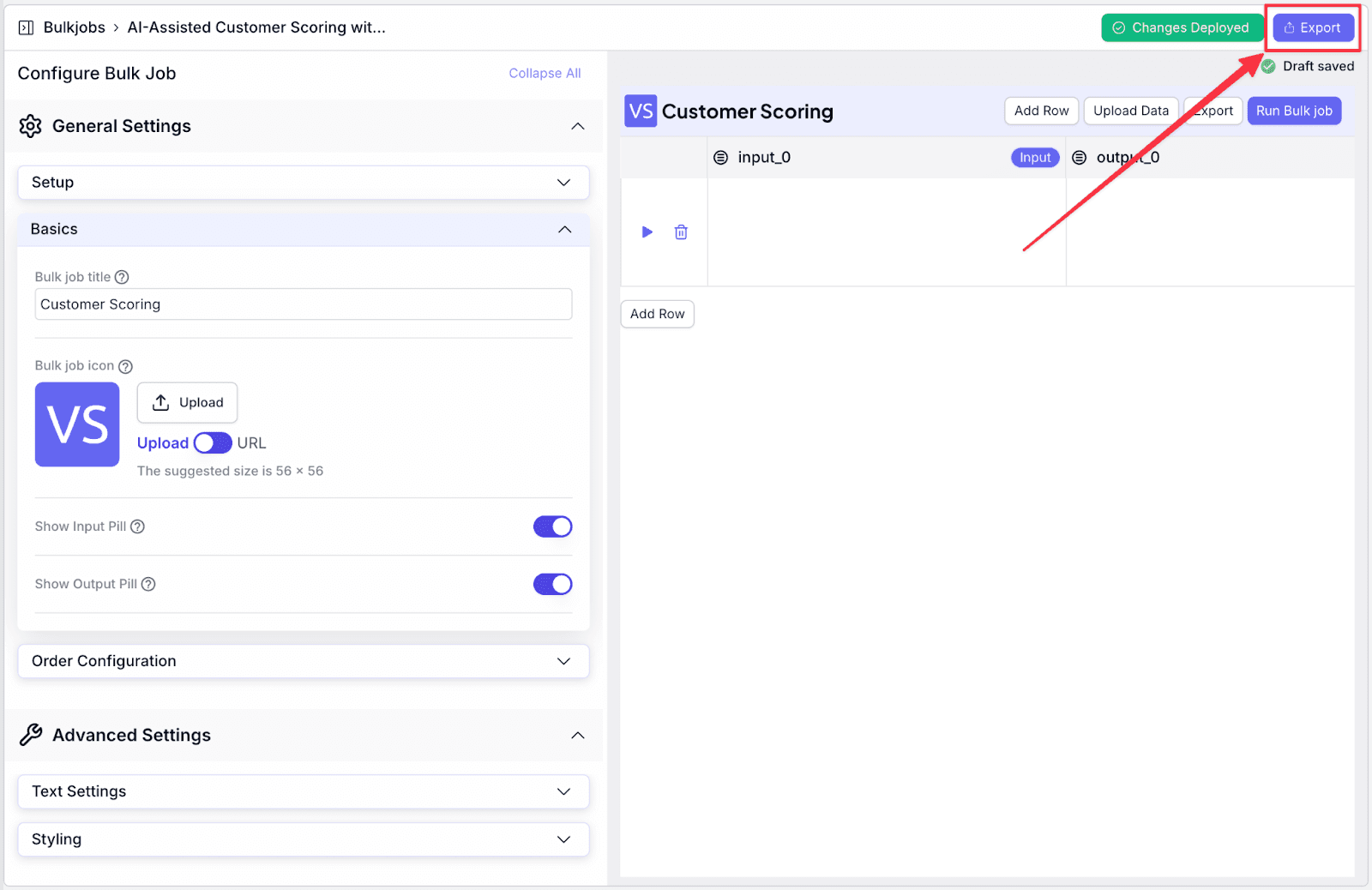
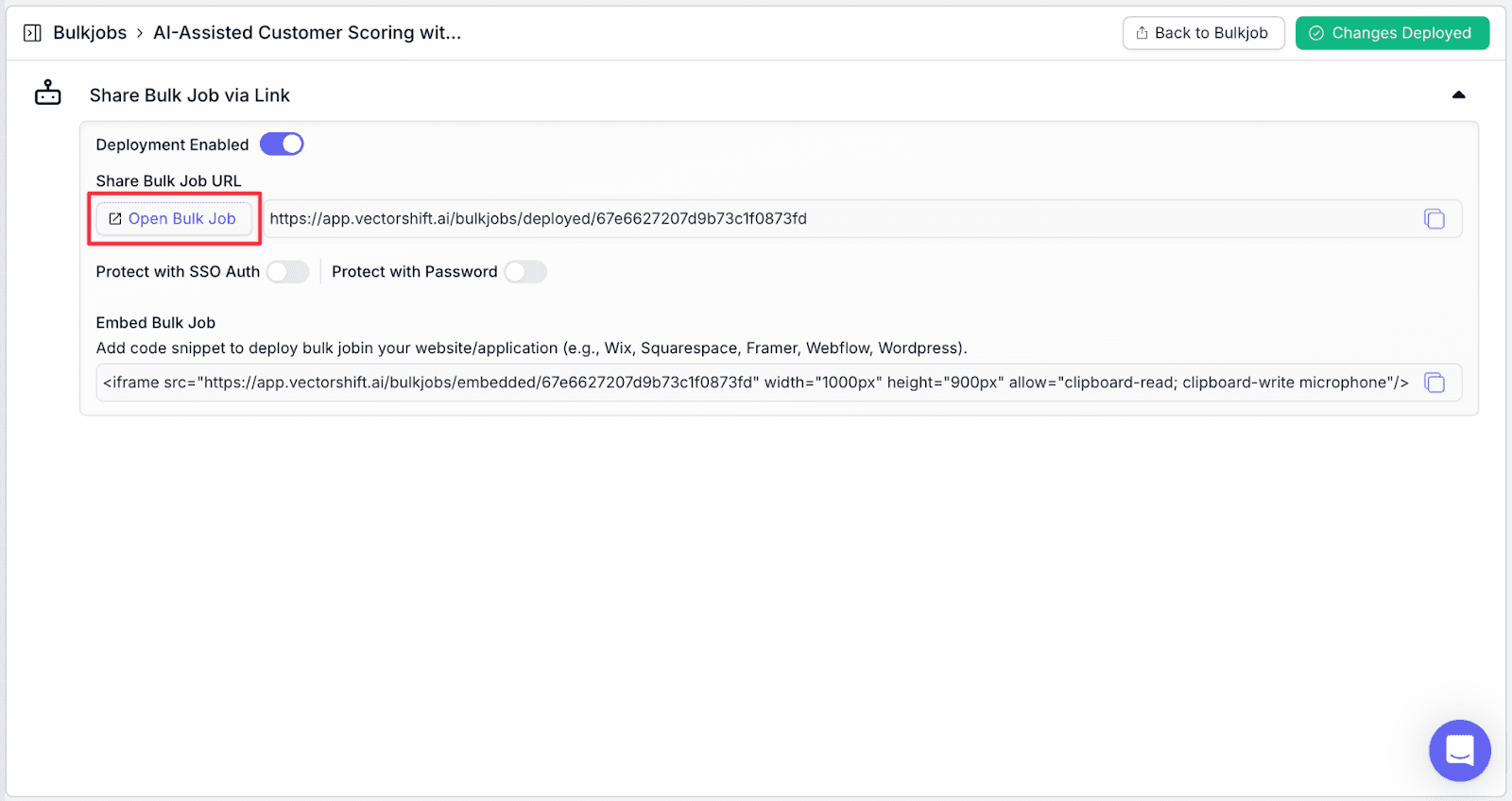
Step 7: Click on the “Open Bulk Job”, or copy the link to share it with your team. In addition, you can protect the interface with a password by toggling on “Protect with Password”.
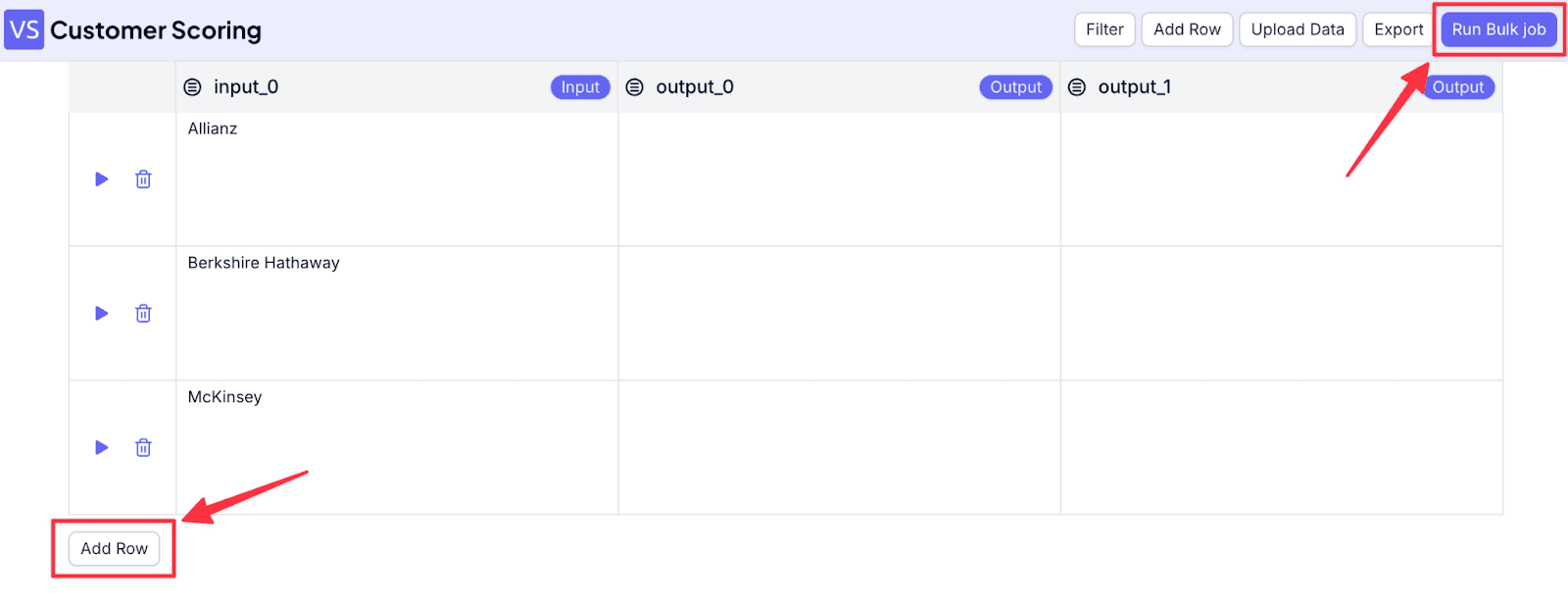
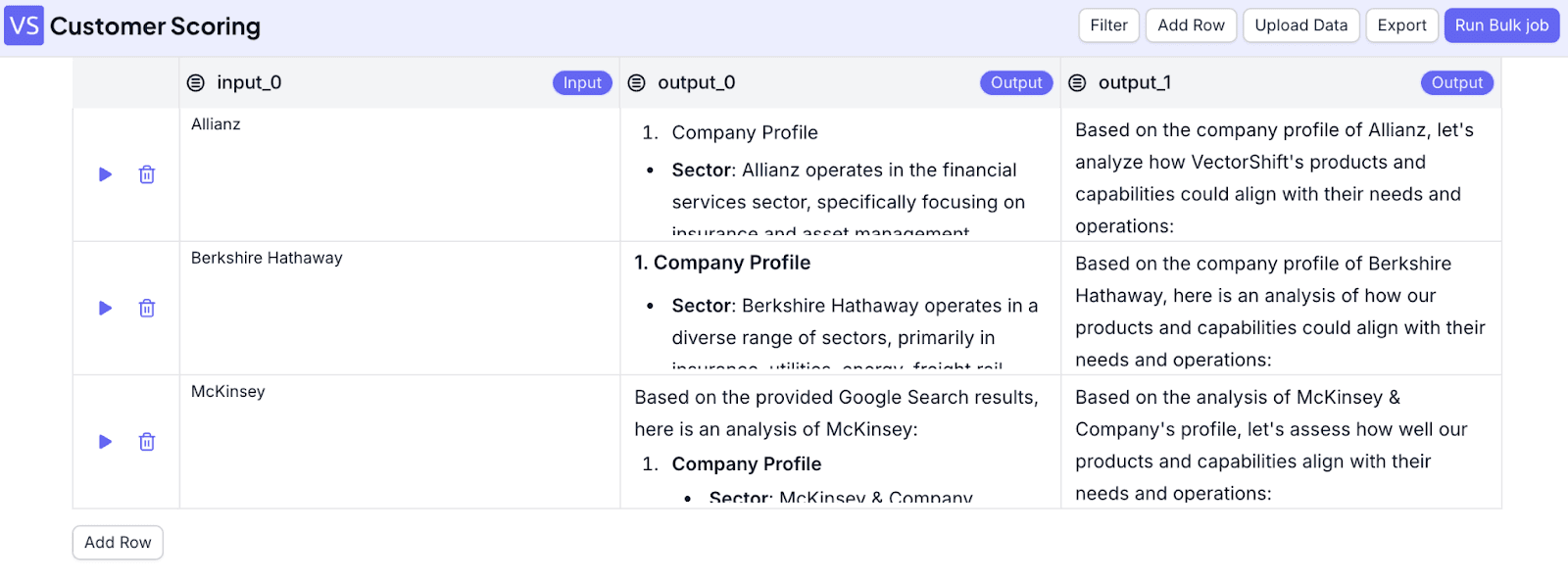
Now, you can see the bulk jobs interface. Add company names to the input field. If you need more rows, just click on “Add Row”. When you finish, click on “Run Bulk Job”.
After the job is finished, you can see the result.
Keep Tracking of the Pipeline Usage
To keep track of any of your pipeline usages, you can go to “Pipeline Analytics”.
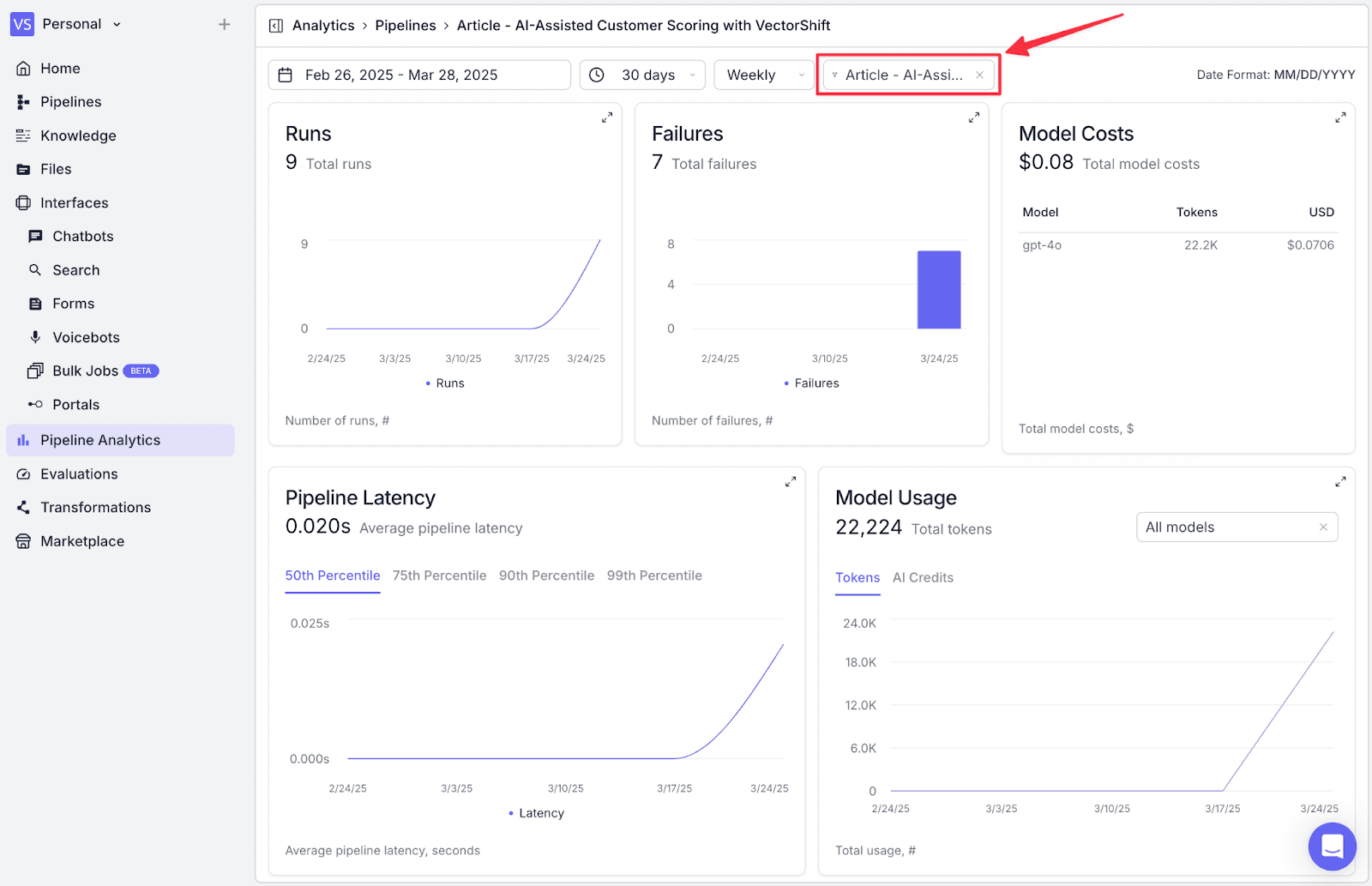
Go to filter, then select the pipeline we’ve just created, and the analytics will show the detail of how many times this pipeline has been executed, failures, model costs, latency, and token usage. As you deploy your solution into production, this helps monitor and trace your usage across your organization.
Conclusion: Generate faster and better leads with VectorShift.
You can extend the functionality of this pipeline further by integrating it with Gmail to automatically draft a proposal, or add more knowledge and information about your business via Google Drive, OneDrive, or other services. VectorShift allows you to compile all of those functionalities and integration into only one platform!
Looking to get started? Create your free account and start scaling your business, or talk with our team!

Albert Mao
Co-Founder
Albert Mao is a co-founder of VectorShift, a no-code AI automation platform and holds a BA in Statistics from Harvard. Previously, he worked at McKinsey & Company, helping Fortune 500 firms with digital transformation and go-to-market strategies.


