

Guides
Feb 28, 2025

Albert Mao
Co-Founder

Transform your organization with AI
Discover how VectorShift can automate workflows with our Secure AI plarform.
Use Case Overview
Legacy call center QA processes require managers to manually review calls — a system that fails to scale and introduces bias. For a 500-seat contact center handling 2 million annual interactions, manual scoring means:
~4,000 hours wasted annually on call evaluations
Majority of agents receive feedback on <1% of their interactions
>$2m in annual labor costs for QA teams
Manual review results in systemic blind spots. Many compliance violations and customer frustration go unidentified. Call centers sit on a gold mine of data that can be used to provide feedback to agents and understand customer / product pain points.
VectorShift enables contact centers to automate quality assurance workflows through AI-powered speech analytics. By evaluating call recordings with an AI workflow:
Every call recording gets evaluated
Every recording is evaluated in a standard way
Data is automatically collected in standard format for easy analysis
Building Steps
Design a pipeline (workflow automation) that
Accepts a call recording as input
Analyze the recordings and create a QA report based on guidelines found in One Drive
Saves the report in a folder in OneDrive
Extracts relevant data from the report and stores it in a database via API
Deploy a form interface on the pipeline allowing QA agents to submit call recordings
Pipeline Overview
The pipeline has 9 nodes: two input nodes, two OneDrive integration nodes, a speech-to-text node, two LLM nodes, an output node, and an API node.
Two Input Nodes:
File input which represents the call recording file
Text input which represents any custom instructions from the evaluator
Speech-to-text Node: The Speech-to-text node will take the recording file input and convert it into text.
Two OneDrive Nodes:
The first one will read QA guidelines and provide it to a LLM so the model has context on how to perform the evaluation
The second one will save the created report in OneDrive
Two LLM Nodes:
The first LLM node generates the quality assurance report.
The second LLM node will translate the result into a JSON which will later be passed to a database via API.
Output Node: To display the assessment report to the evaluator.
API Node: To send the JSON result to a database.
The Pipeline Design Overview
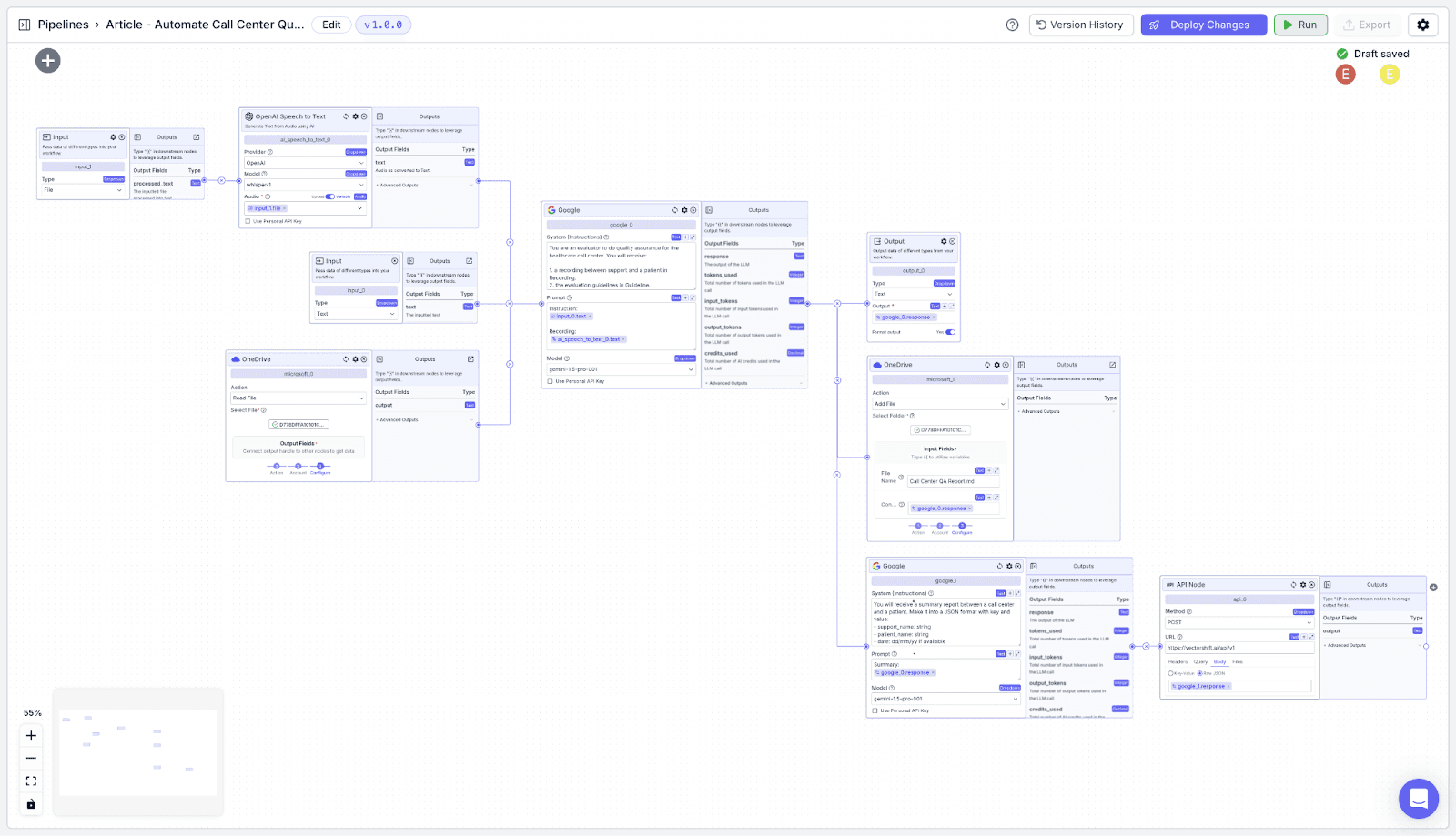
1. Designing the Pipeline
Input Node (Recording file)
Take an Input Node and from the “Type” list, choose “File” type. This allows the pipeline to take the recording file as input.
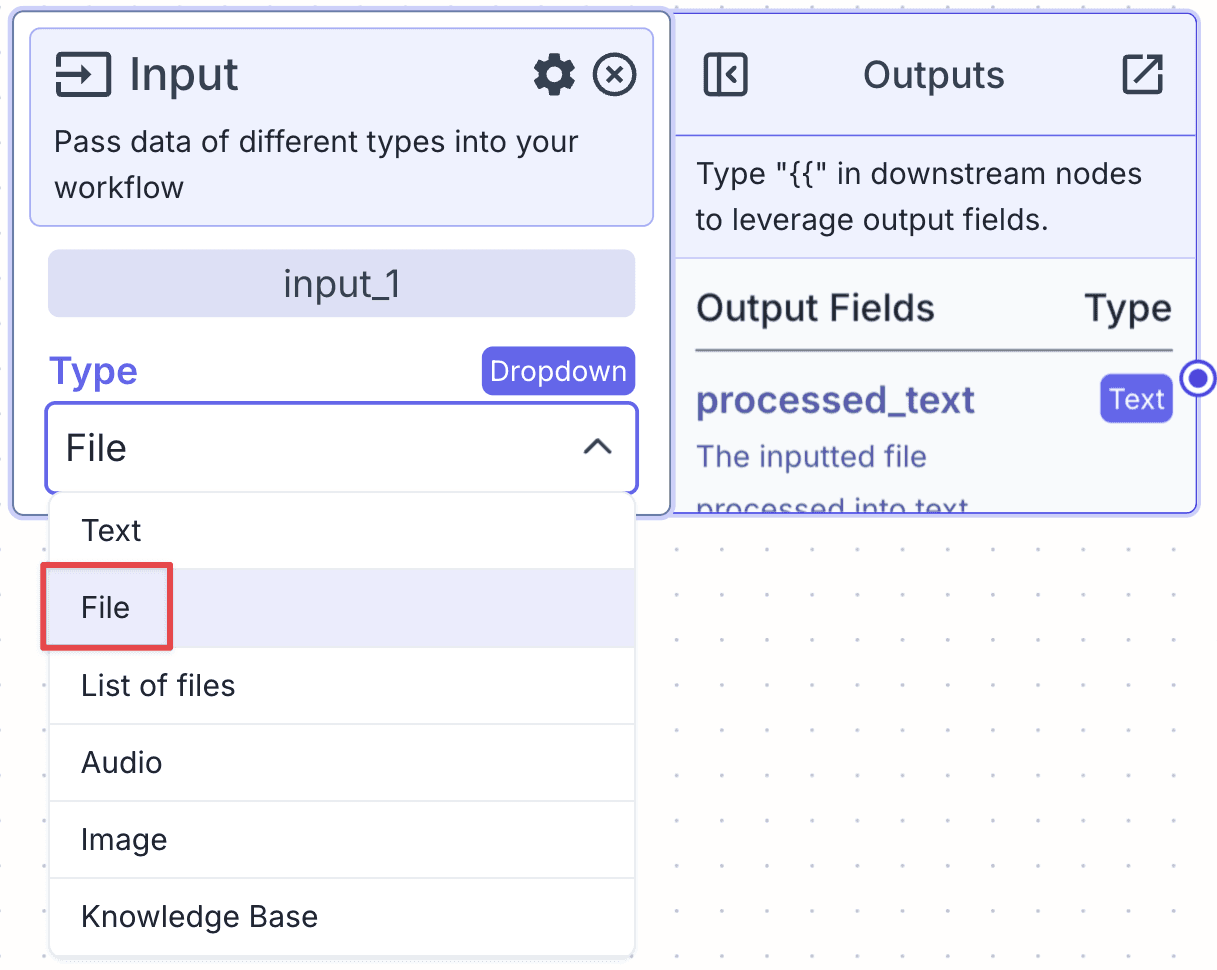
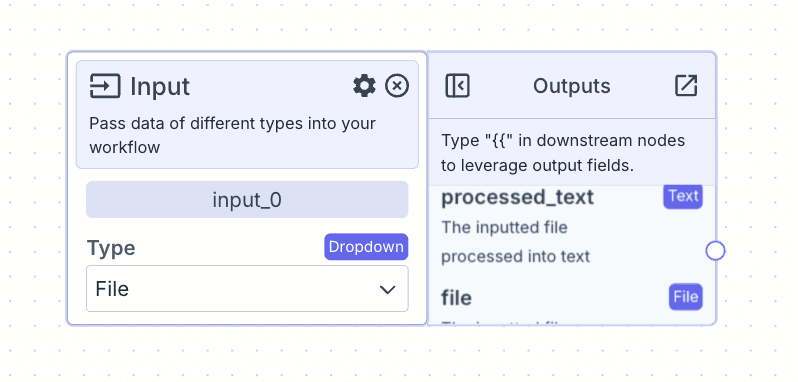
Each node in VectorShift has a name at the top of each node (e.g., input_1) and output field(s), which are found in the right-hand pane of each node (e.g., the input node of type file only has two output fields: processed_text and file).
Speech-to-Text Node
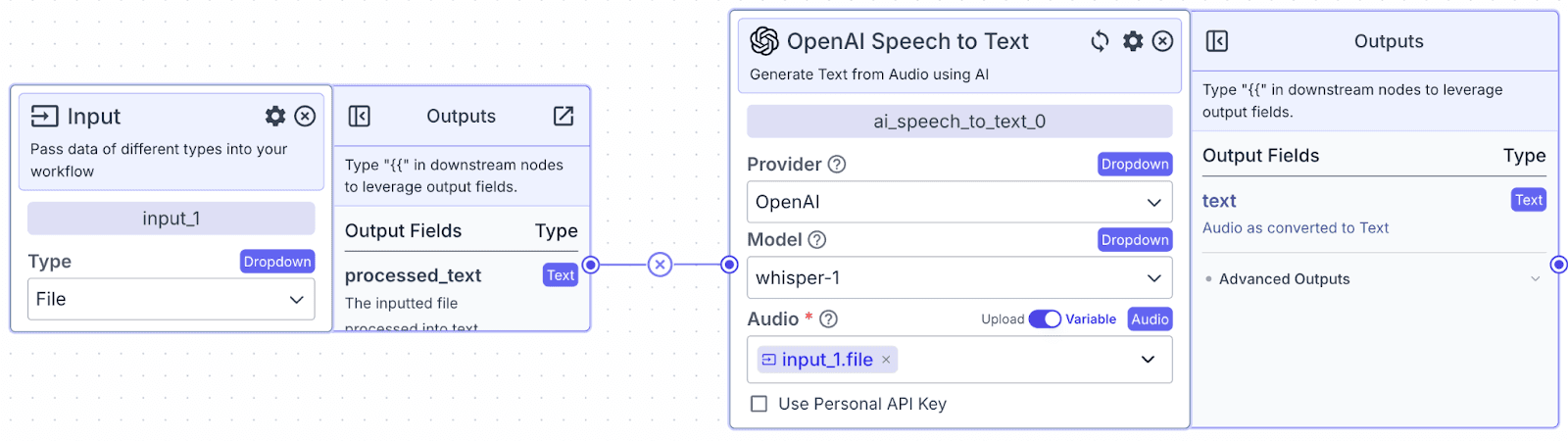
We will connect the file input node with the Speech-to-Text node to convert the recording into text.
To reference specific data fields from other nodes, you have to do two things:
Connect the two nodes.
Reference the desired data using a variable.
Variables in VectorShift all have the same structure:
You can also create variables by typing “{{“ in any text field, which opens the variable builder. To reference the file from the input node, you call the variable:
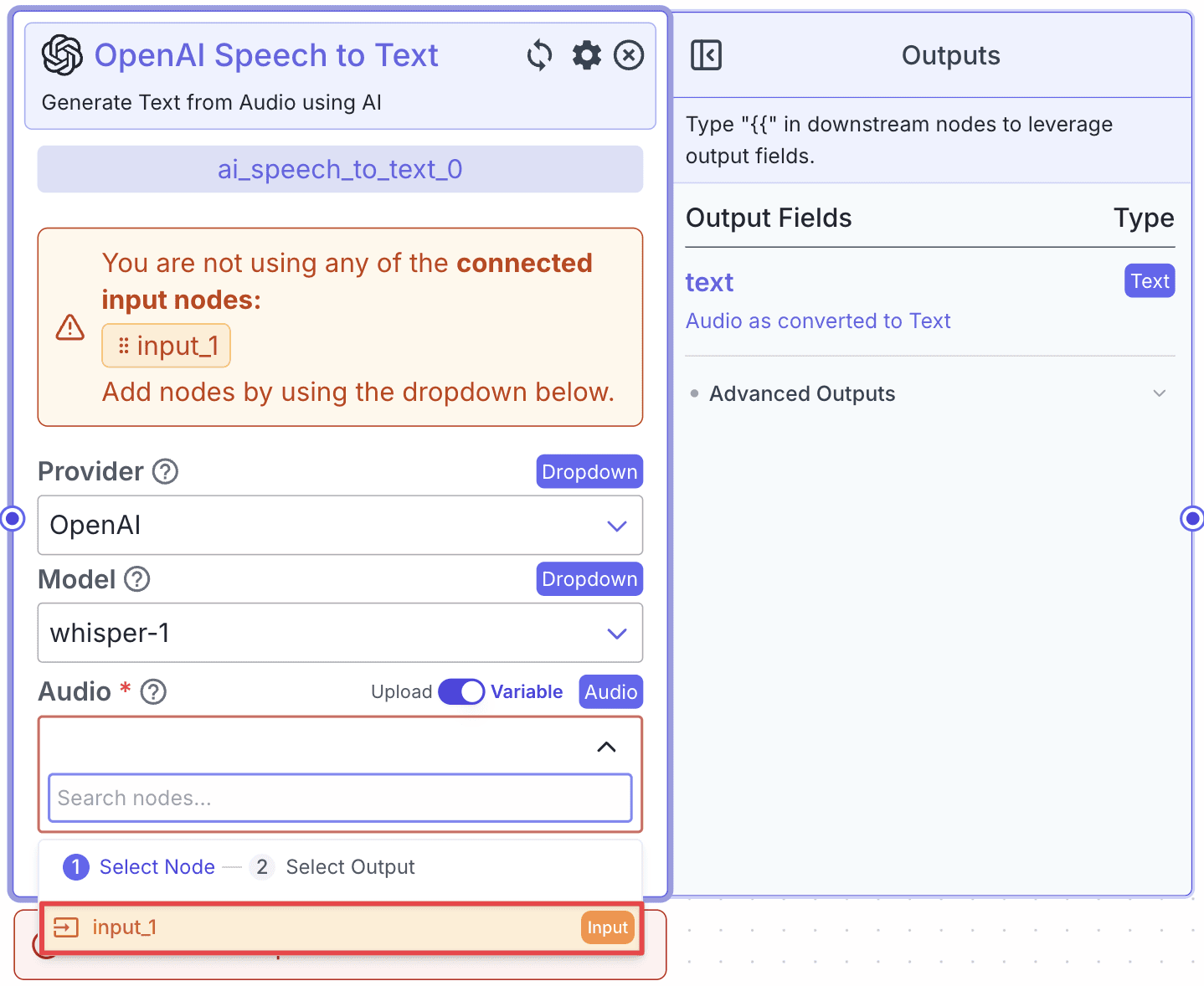
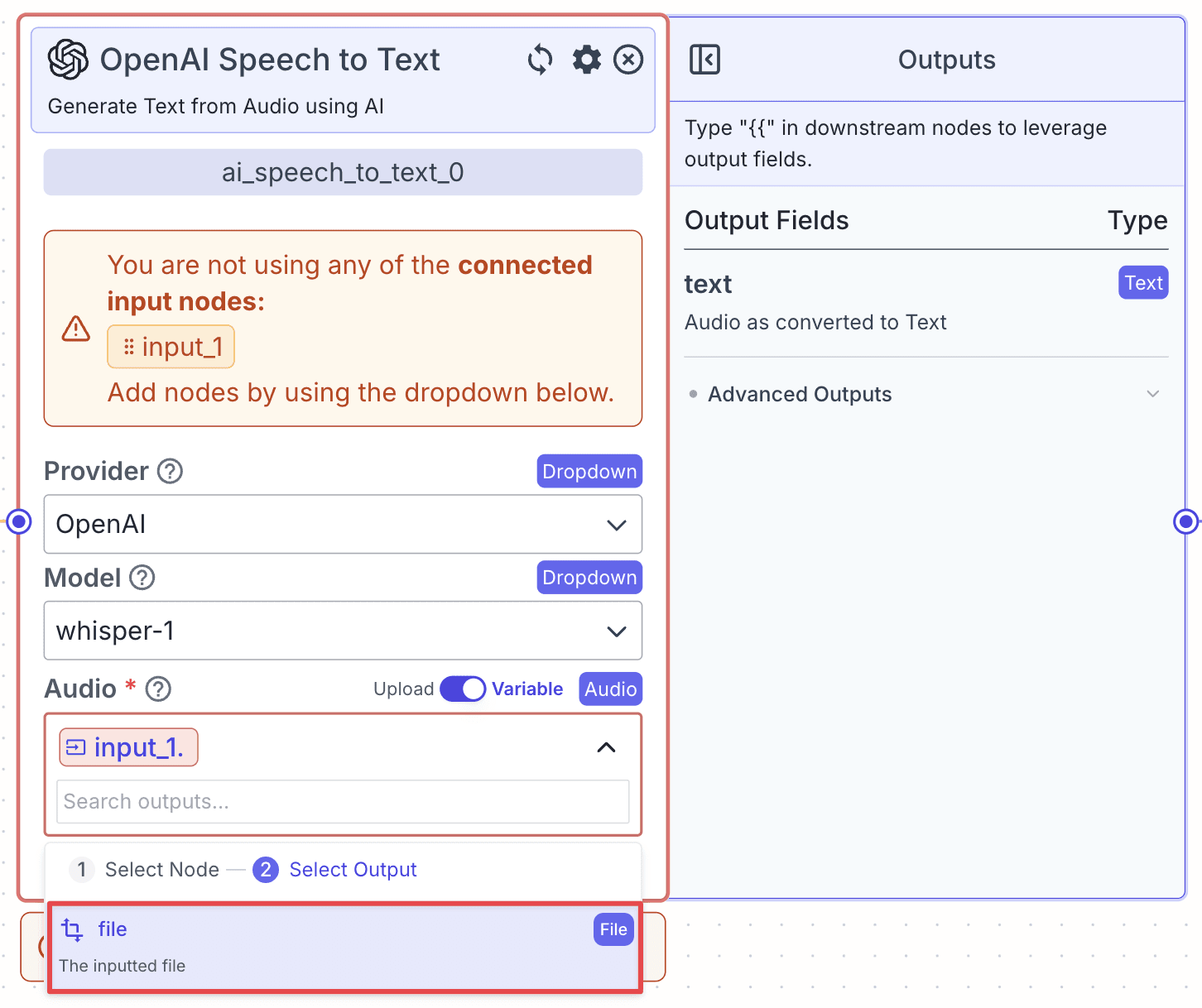
Step 1: Take the Speech-to-text node and connect it with the Input Node.

Step 2: Go to the “Audio” field and select node “input_1”, then choose “file” for the output field. This means the Speech-to-text node will take a file as input from the “input_1” node.
When the pipeline runs, the data from the referenced output field is passed to the connected nodes.
Input Node (Custom Instruction)
Add one more input text to accept custom instructions from the evaluator. Keep the “Type” row as “Text”.
OneDrive Node (Read QA Guidelines)
We will connect with OneDrive to fetchQuality Assessment guideline which will be used to evaluate each recording.
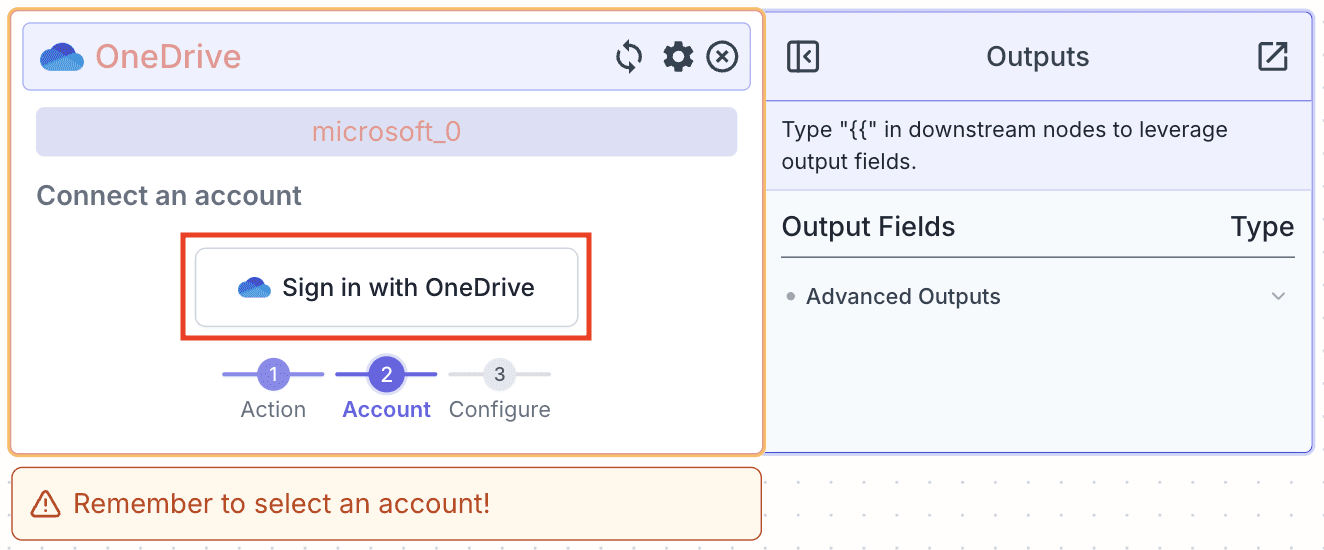
Step 1: Search for the “OneDrive” node.
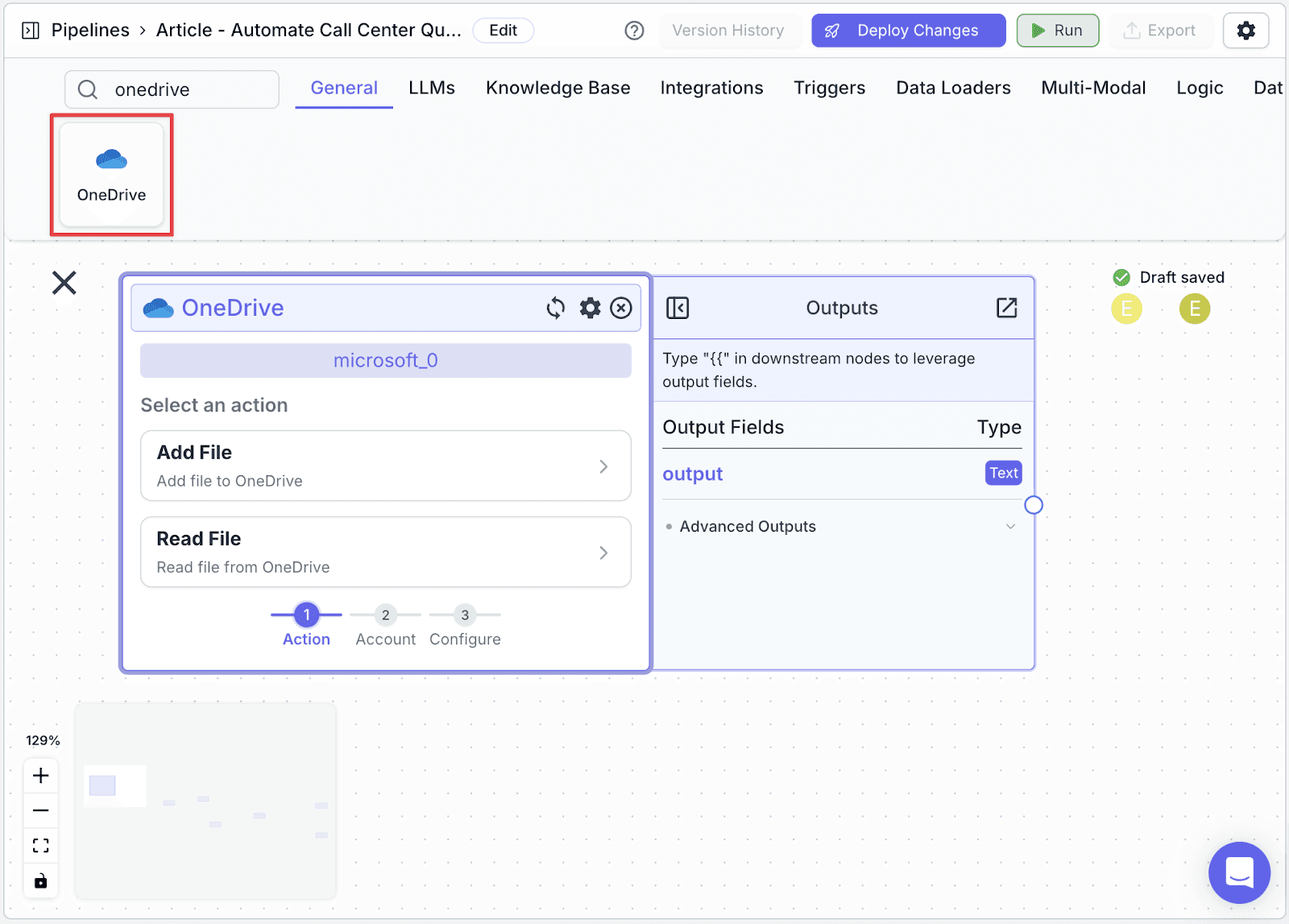
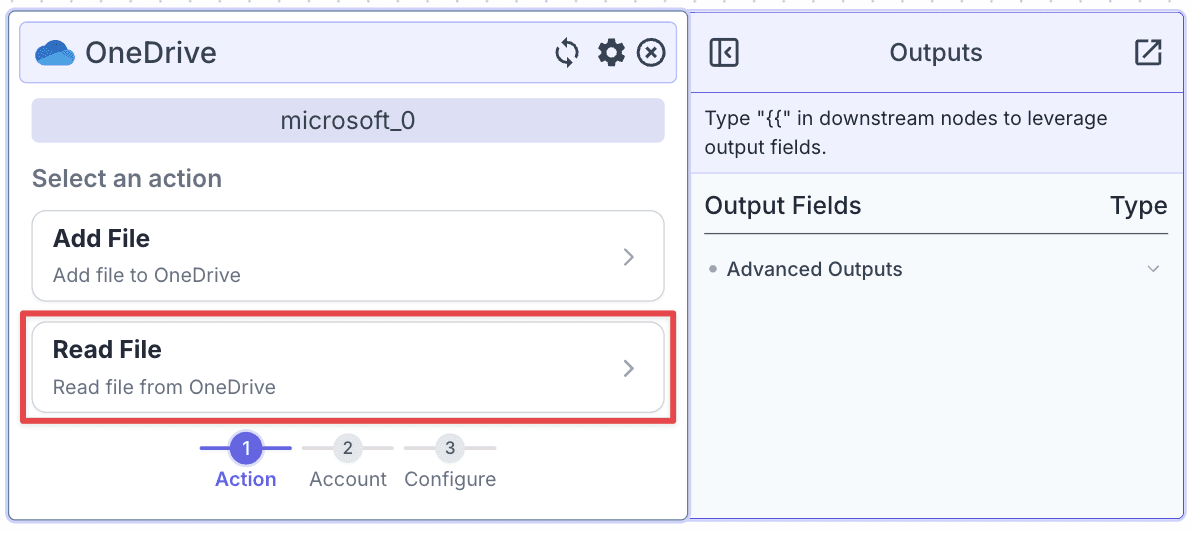
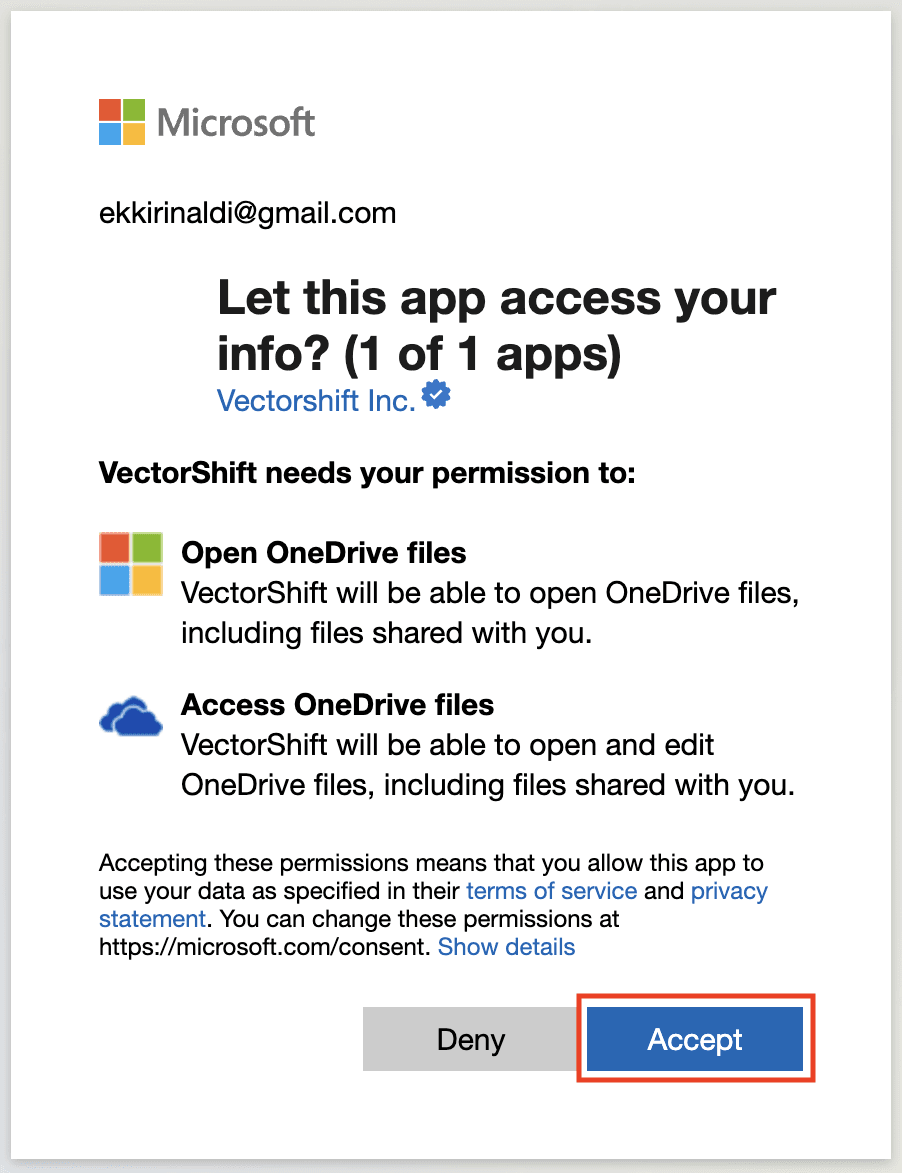
Step 2: Click on “Read File” and sign in with your OneDrive account. Click “Accept” to allow VectorShift to access your OneDrive.
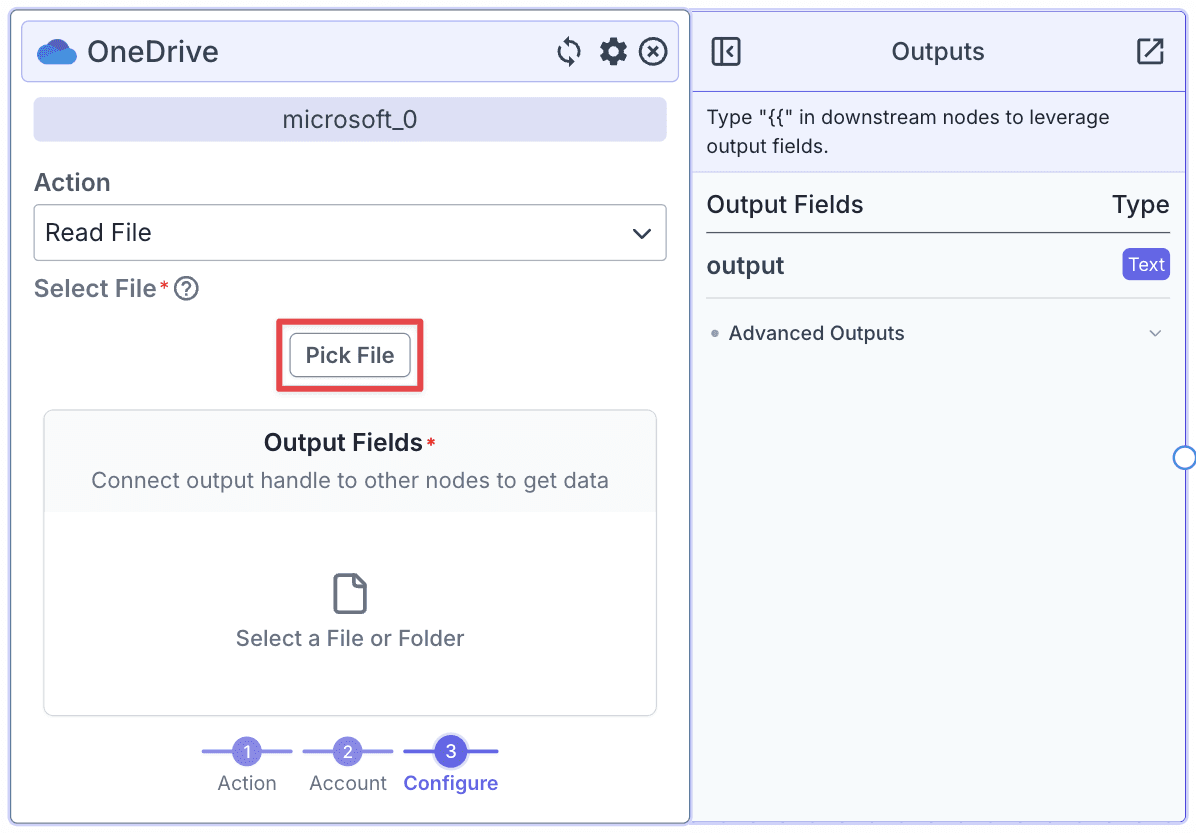
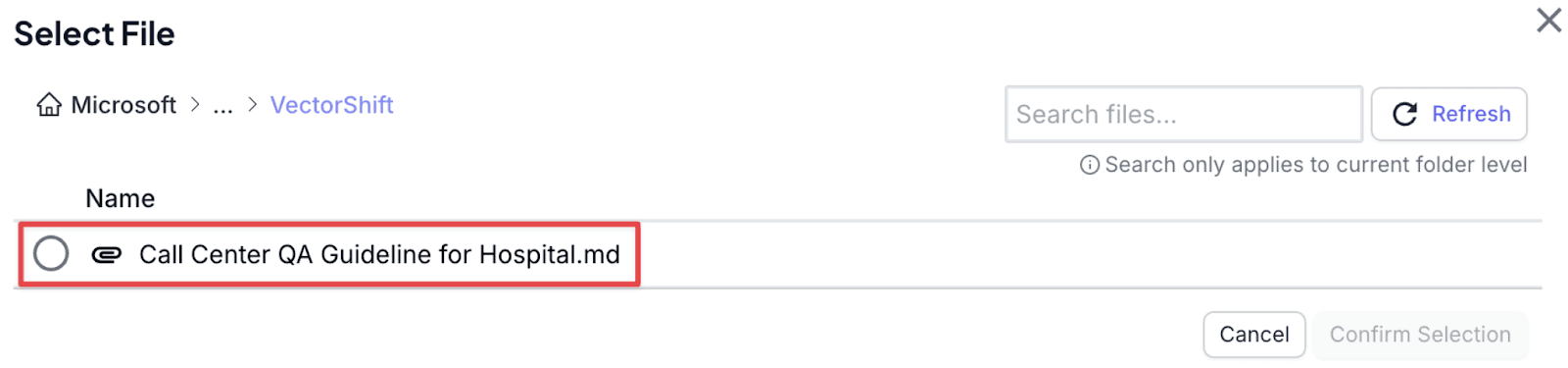
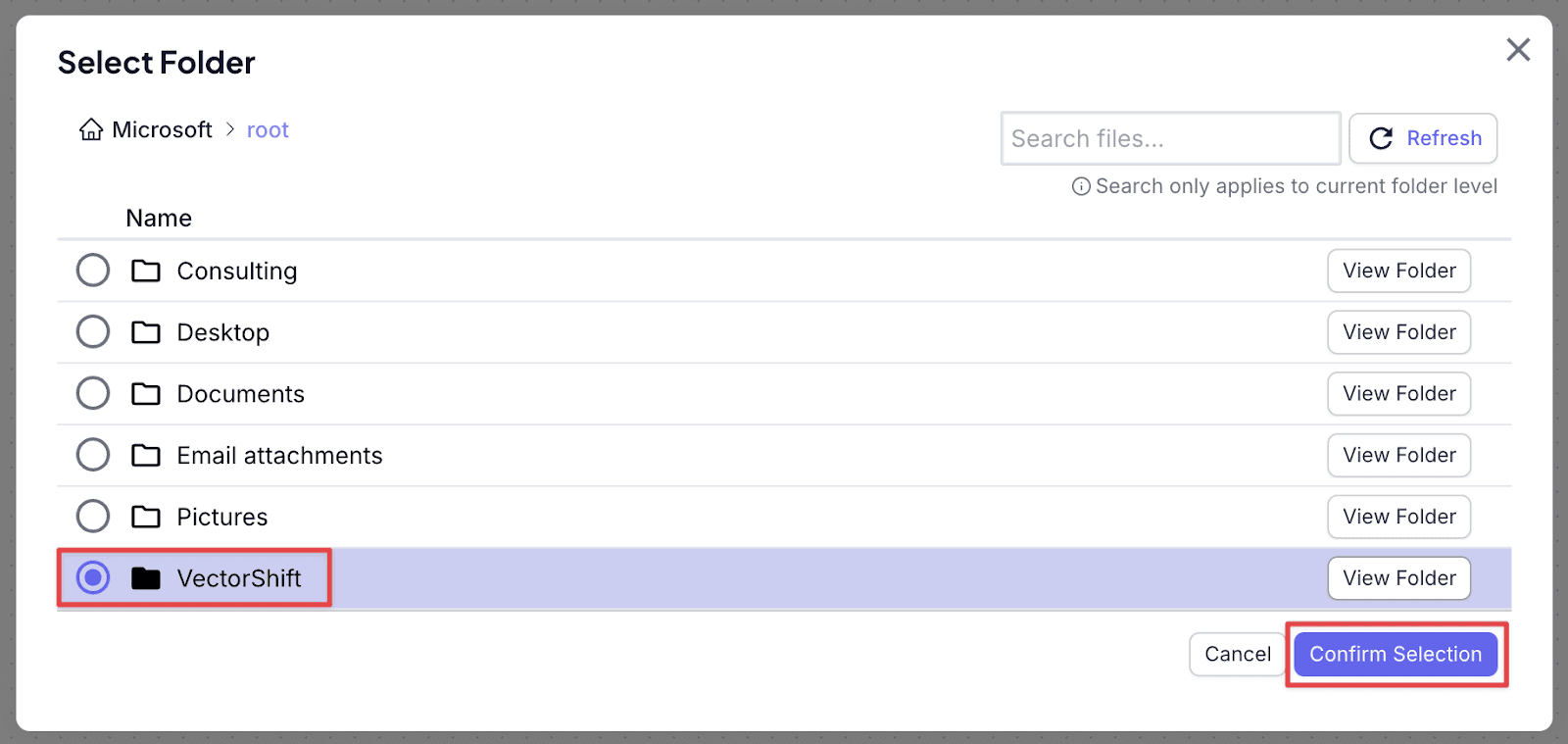
Step 3: Click on “Pick File” and look for the relevant file(s) (here, the quality assurance document guideline). Click on the file, and “Confirm Selection”

LLM Node (QA Report Generator)
LLM node will be used to generate a QA report for each recording file processed, while following instructions from the QA guidelines document. We will use Google Gemini which gives us a large context window input (up to 2 million input tokens).
Step 1: Connect all three inputs (the call transcript, the guidelines, and evaluator instructions) with Google LLM Node.
The LLM node has two fields: “System (Instructions)” and “Prompt”.
“System (Instructions)” defines how you want the LLM to behave. You can use the template below:
Within the “Prompt”, you can pass data from other nodes. Use the prompt below to pass all input into LLM:
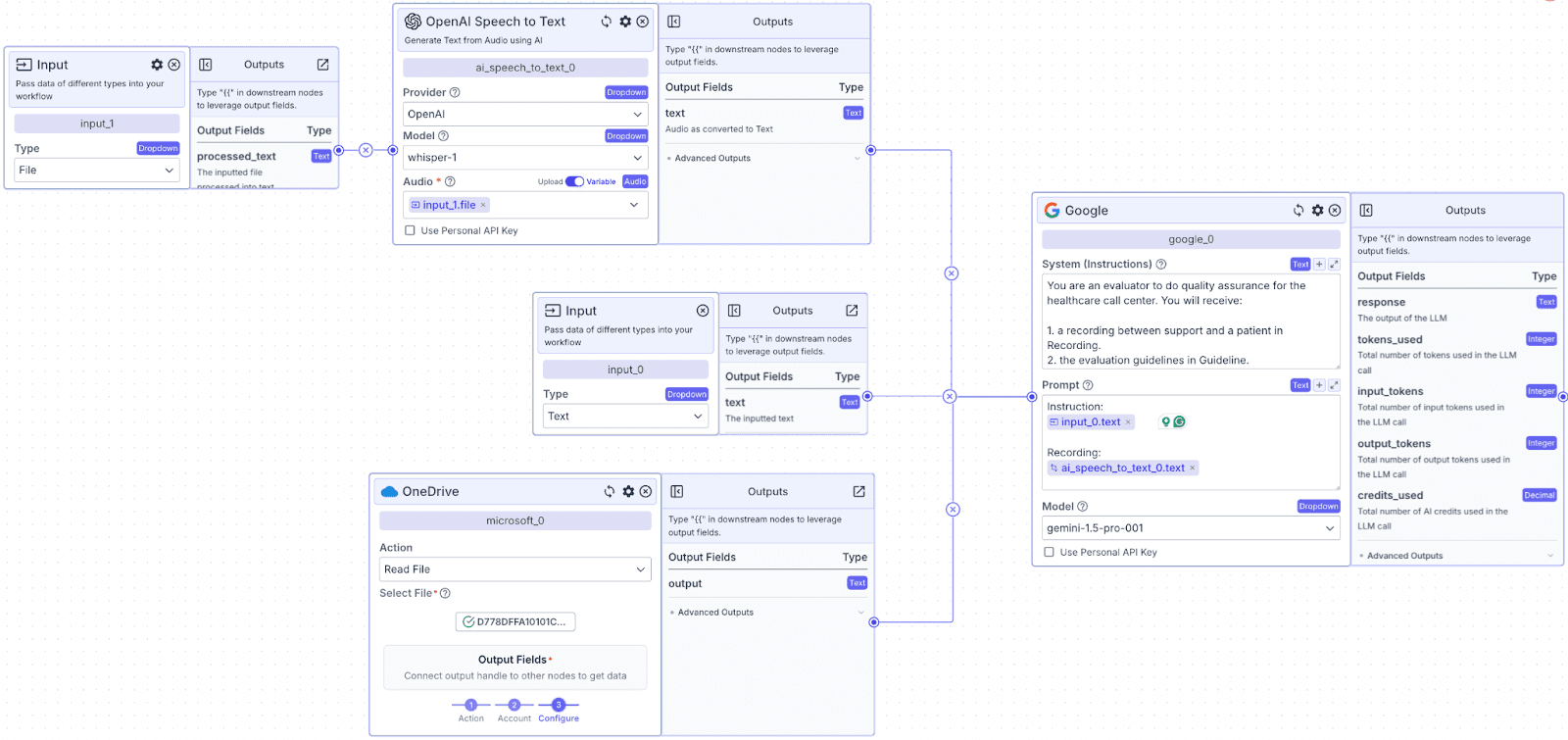

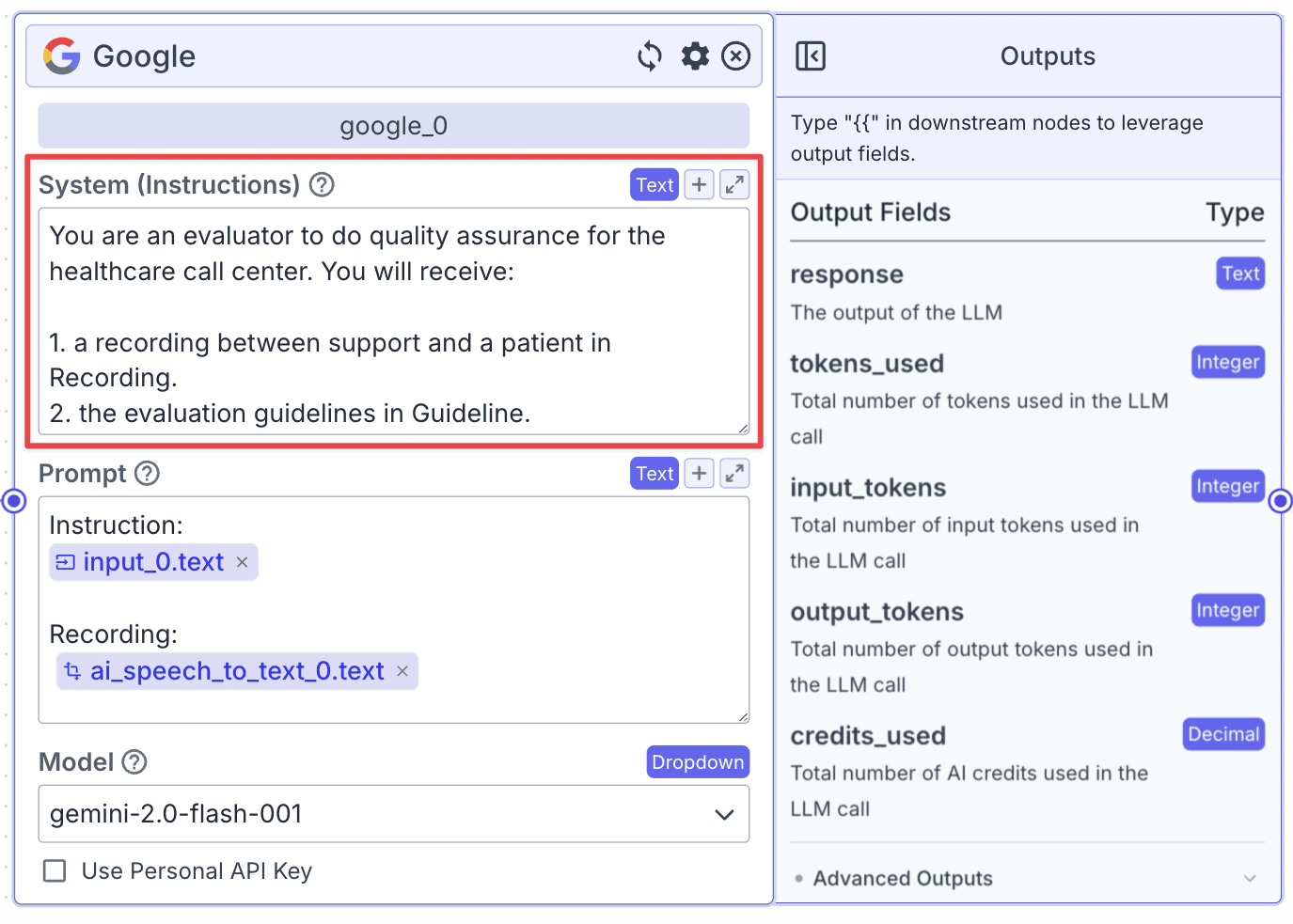

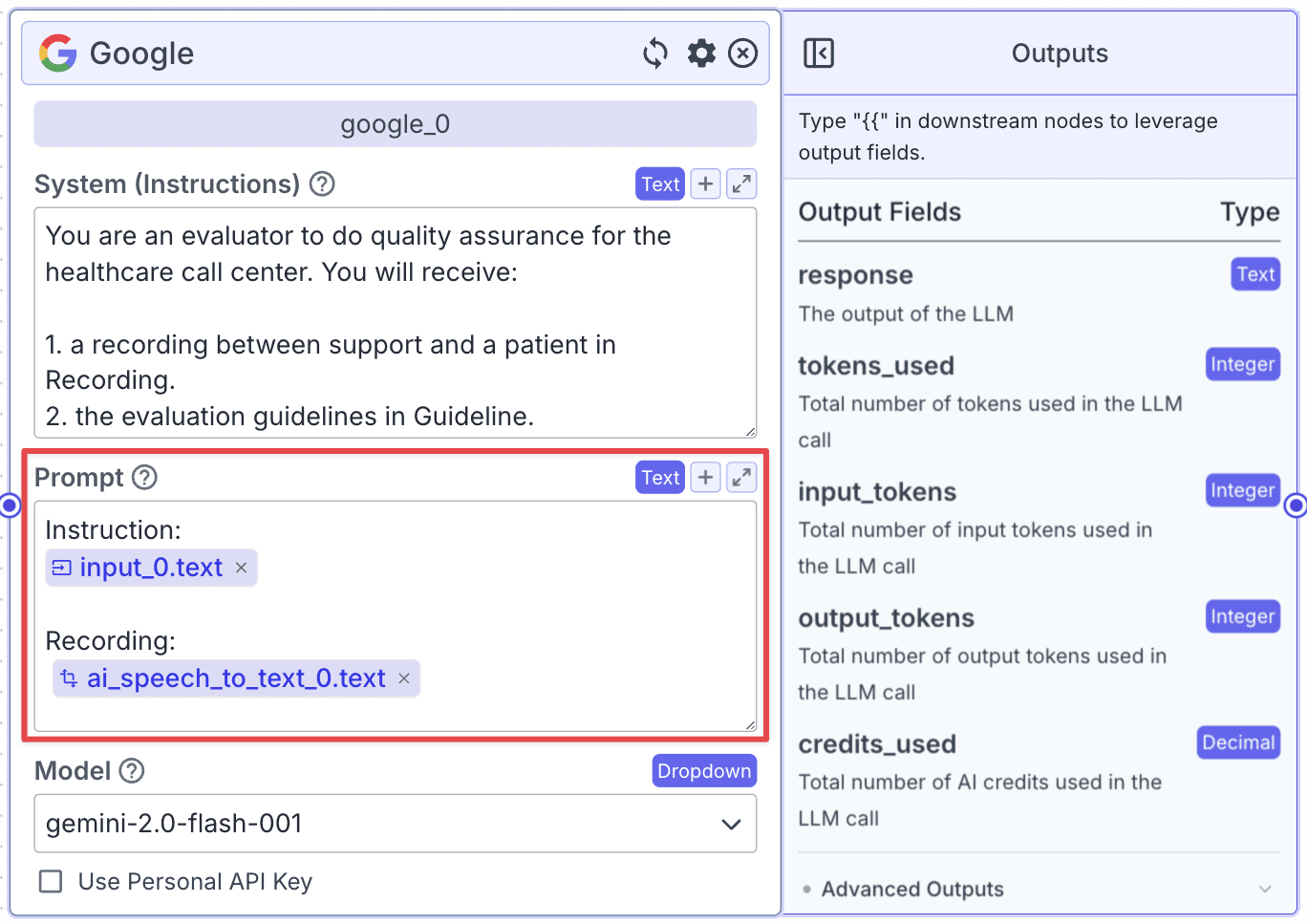
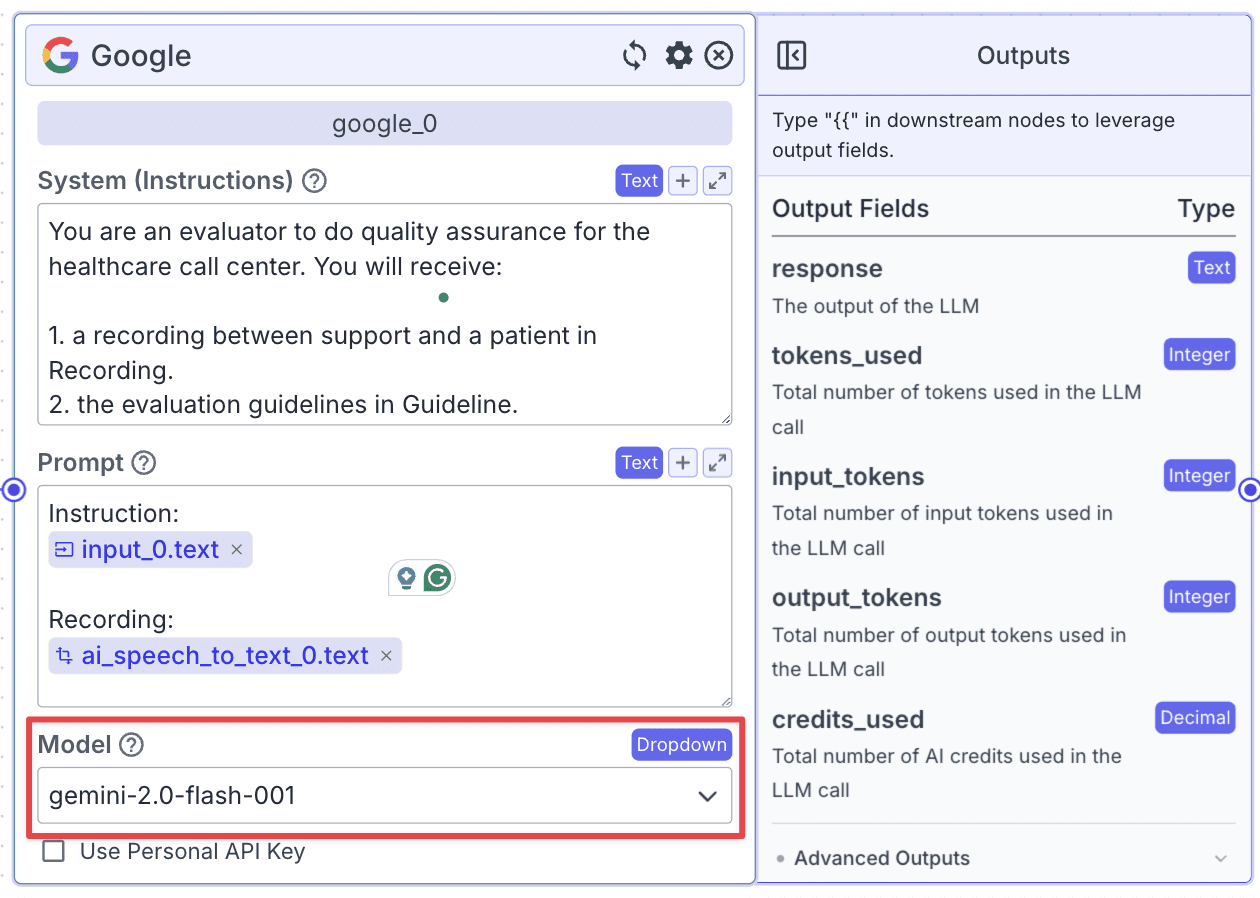
Step 2: Change the Model to Gemini 1.5 by clicking on the “Model” dropdown and selecting “gemini-1.5-pro-001”.
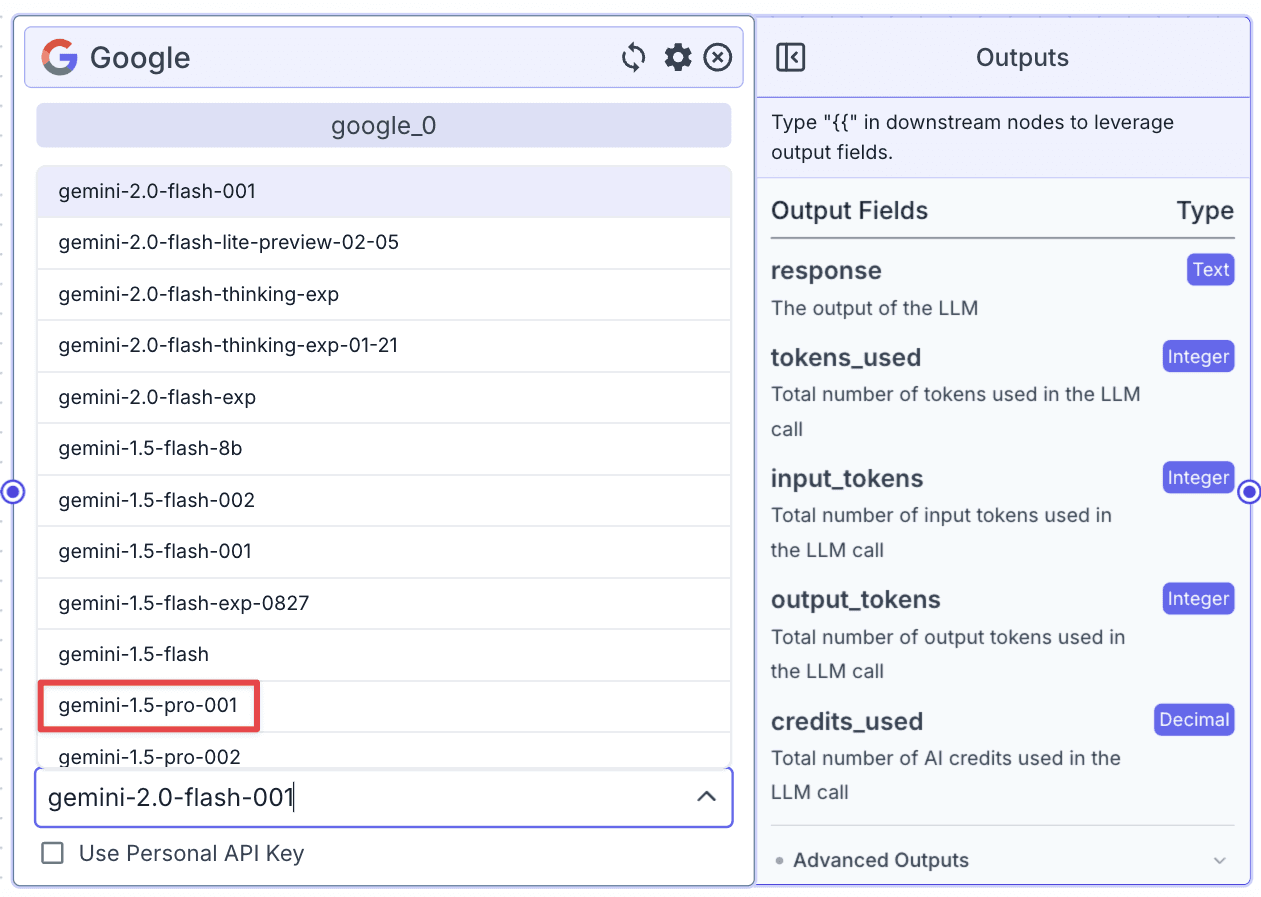
Output Node
The output node allow the evaluator to view the report. Connect the Google LLM with Output Node and write {{google_0.response}} in the Output field.
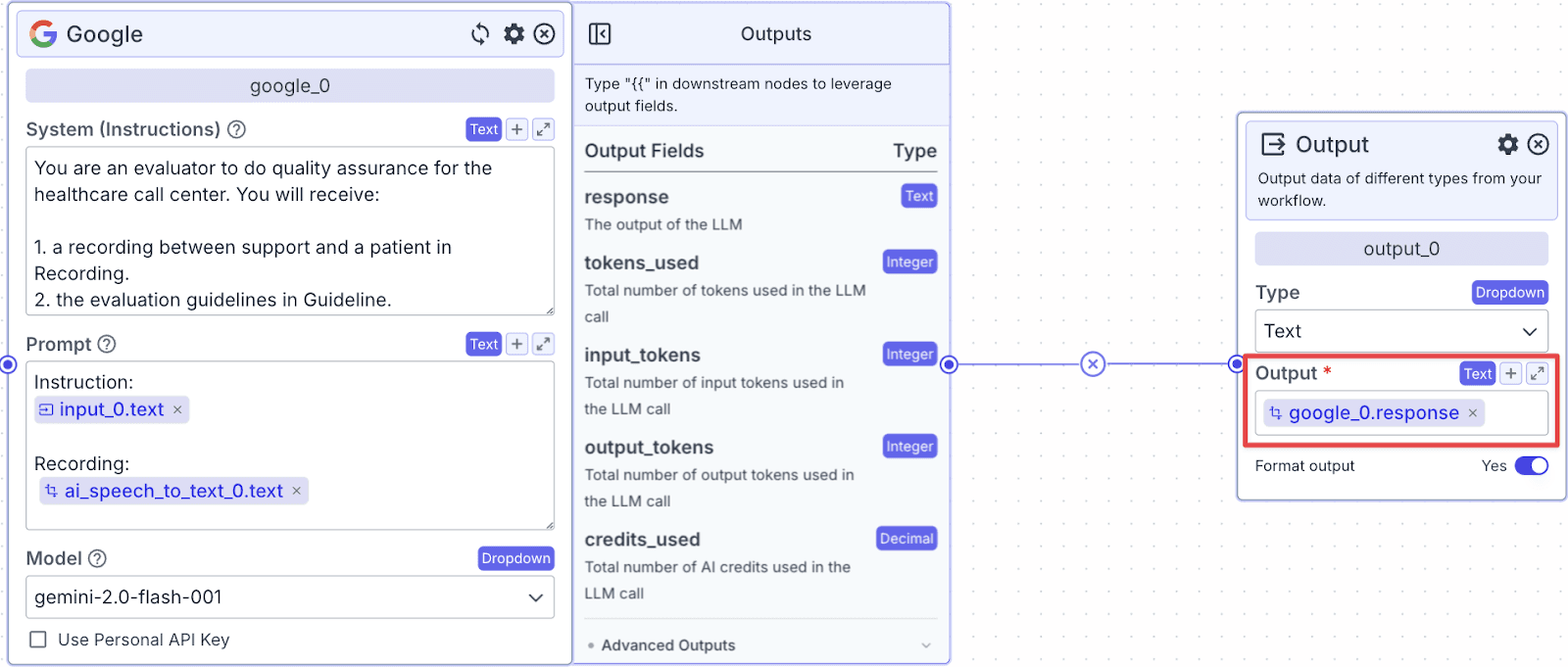
OneDrive Node (Save report in OneDrive)
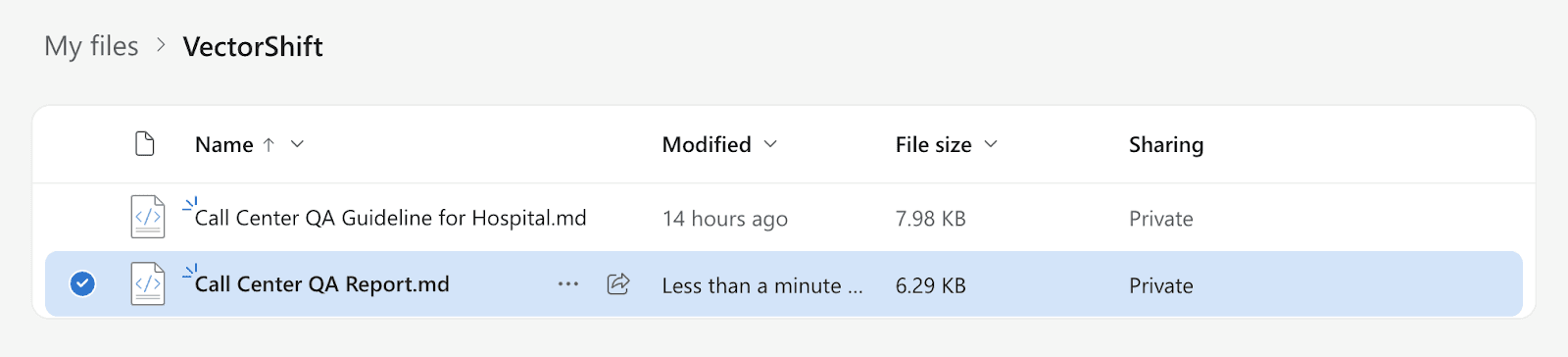
To make the evaluation traceable, each report will be saved into OneDrive.
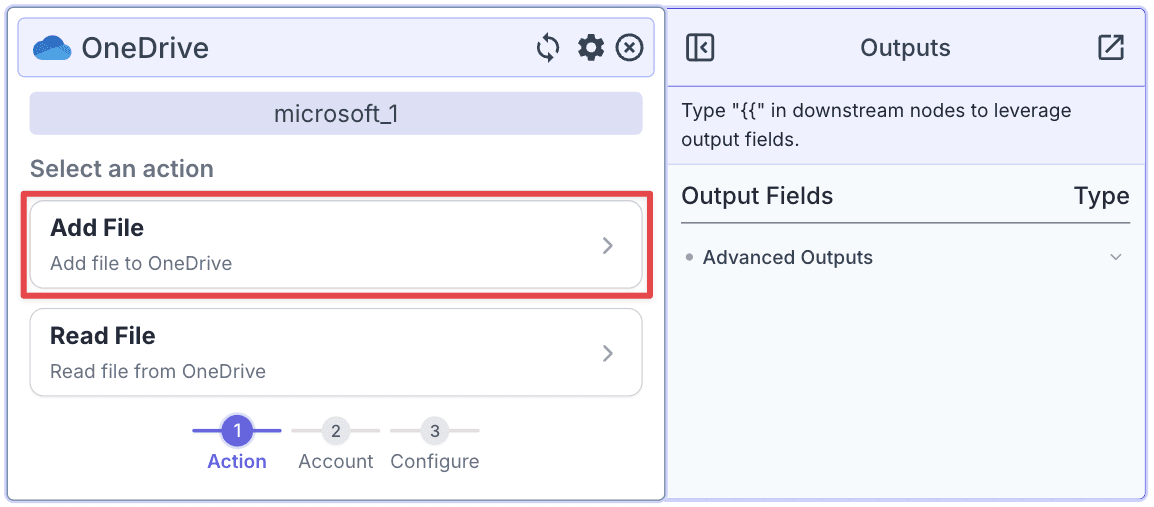
Step 1: Add one more OneDrive Node, choose “Add File”, then click “Next”.
Step 2: Choose where you want to save the report by clicking on the “Pick Folder”. Then select the folder. Click on “Confirm Selection” afterwards.

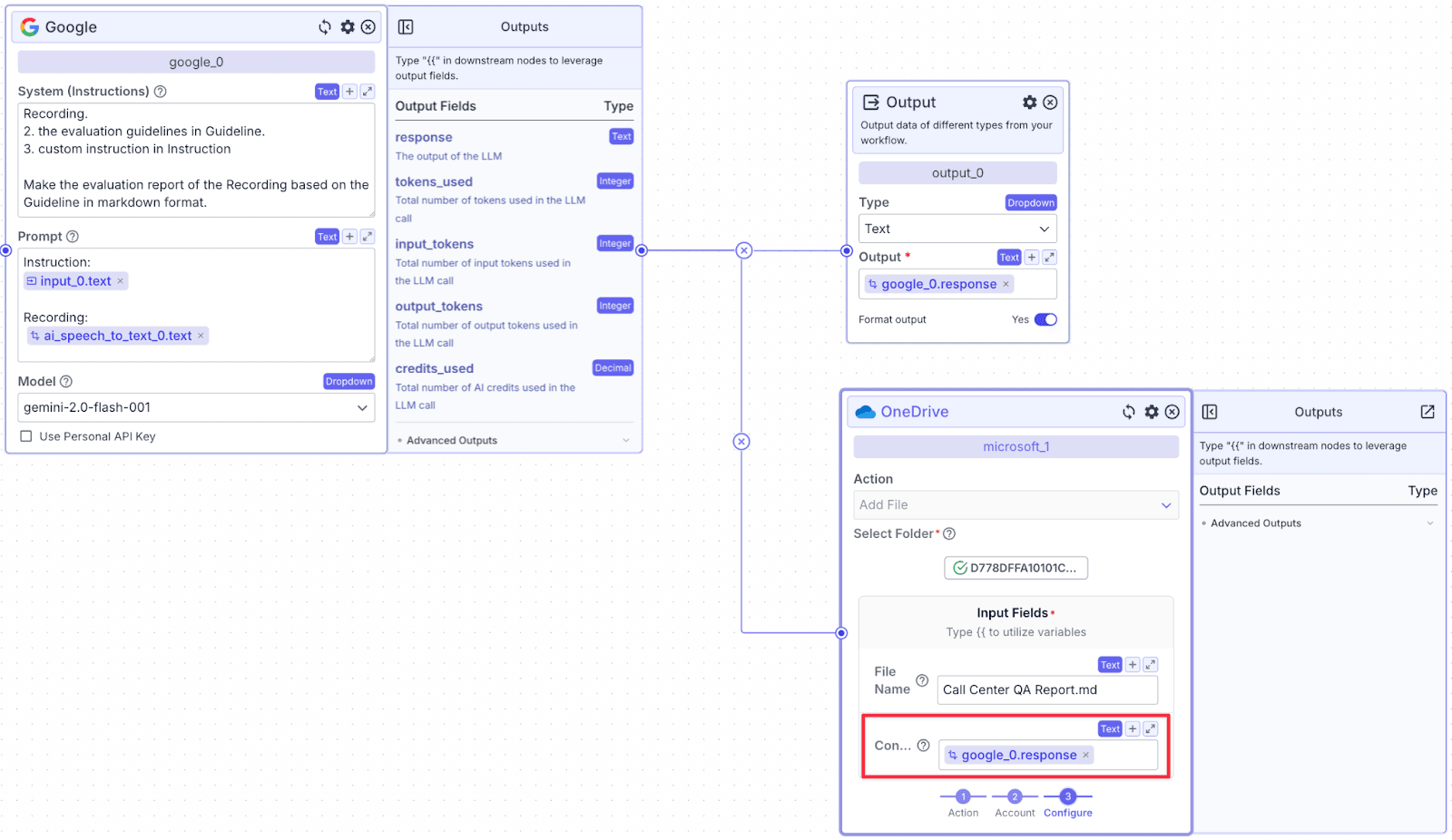
Step 3: Connect the Google LLM node with OneDrive. Provide a name for the file, and reference the response from the LLM, {{google_0.response}}, within “Content”.
LLM Node (Convert to JSON)
We need another LLM to convert the report into a JSON which will later be sent to a database via API.
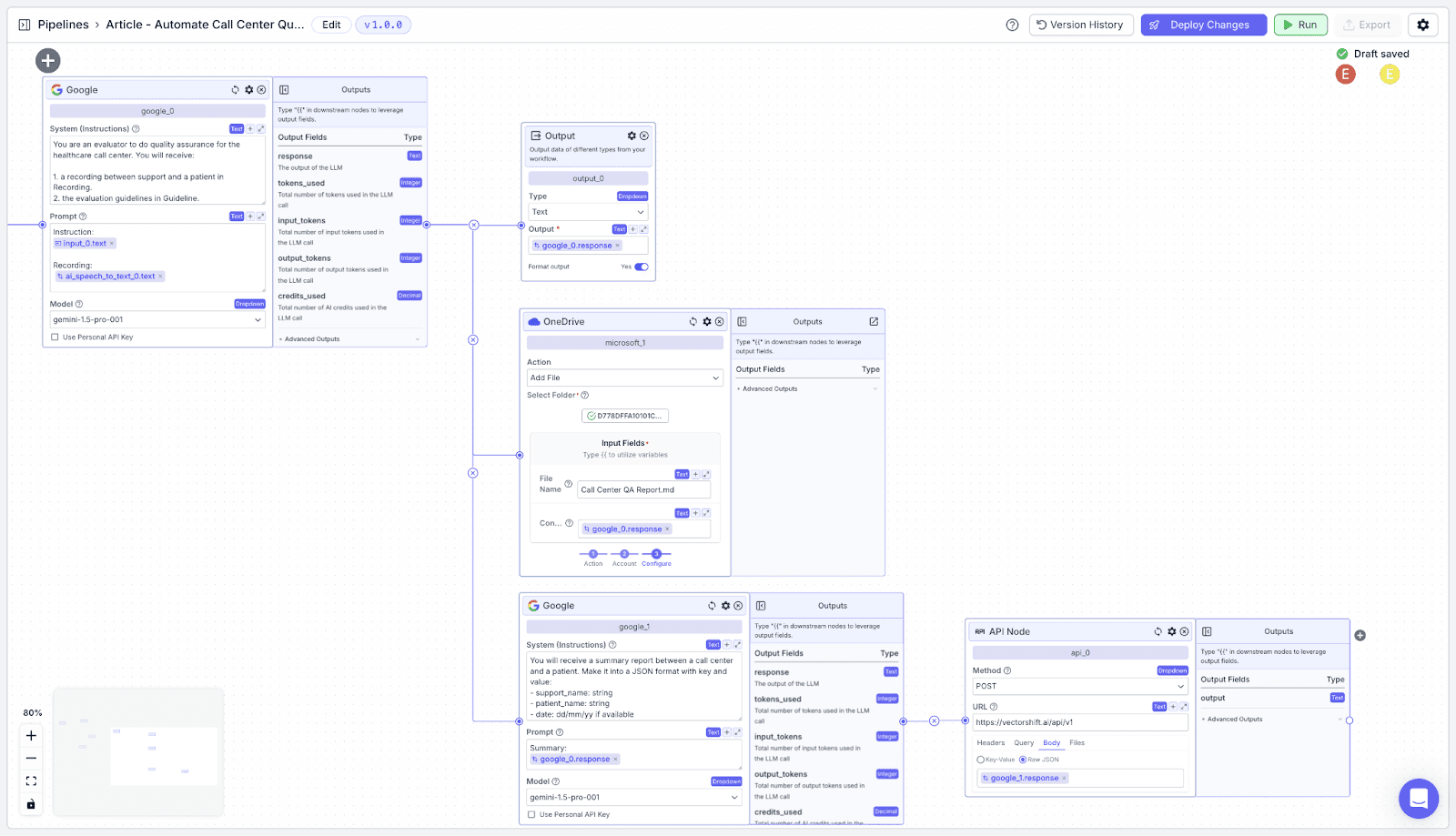
Step 1: Add an LLM node and connect it with the previous LLM Node.
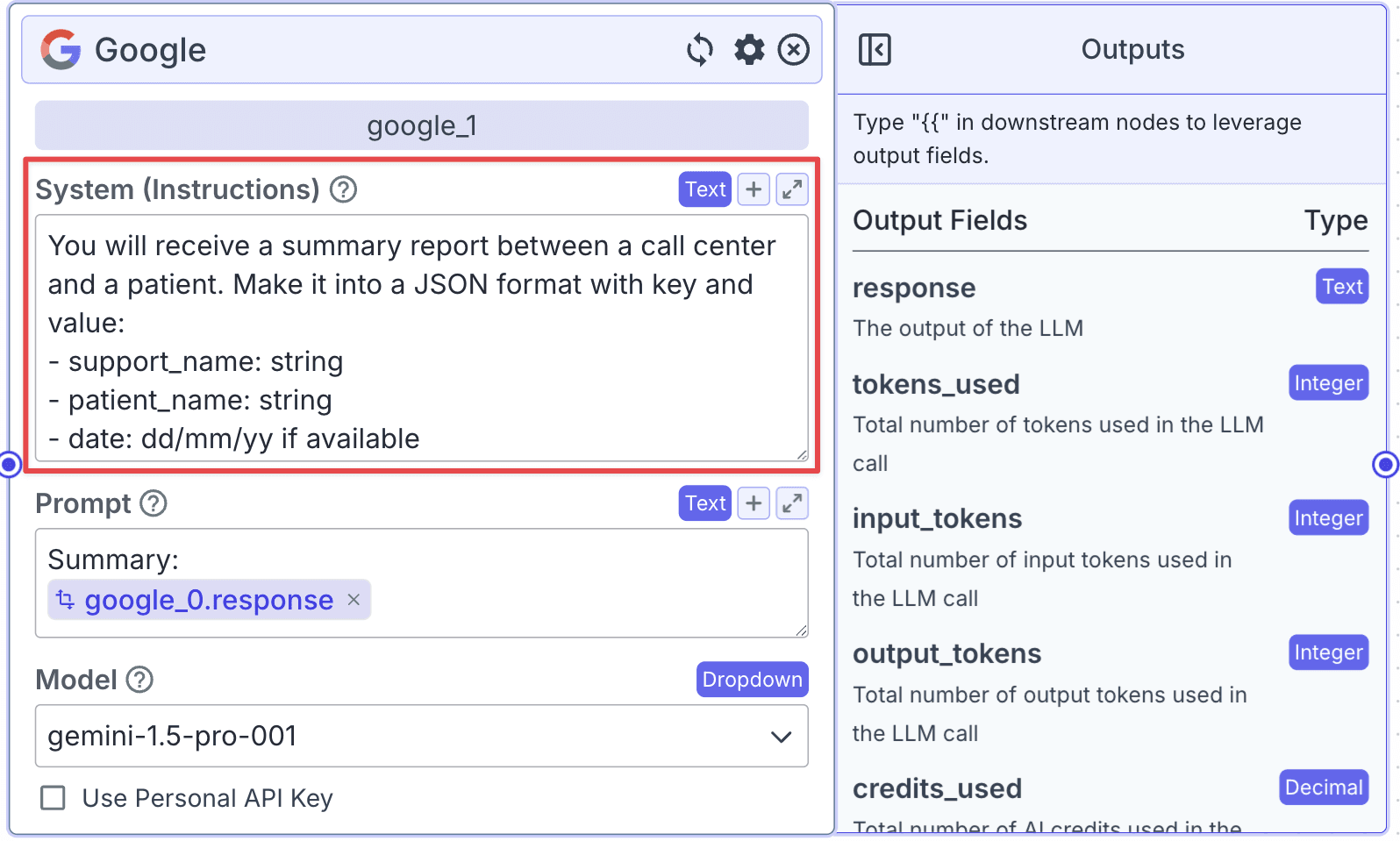
System (Instructions):
Within the “Prompt”, you can pass data from other nodes. Use the prompt below to pass all input into LLM:


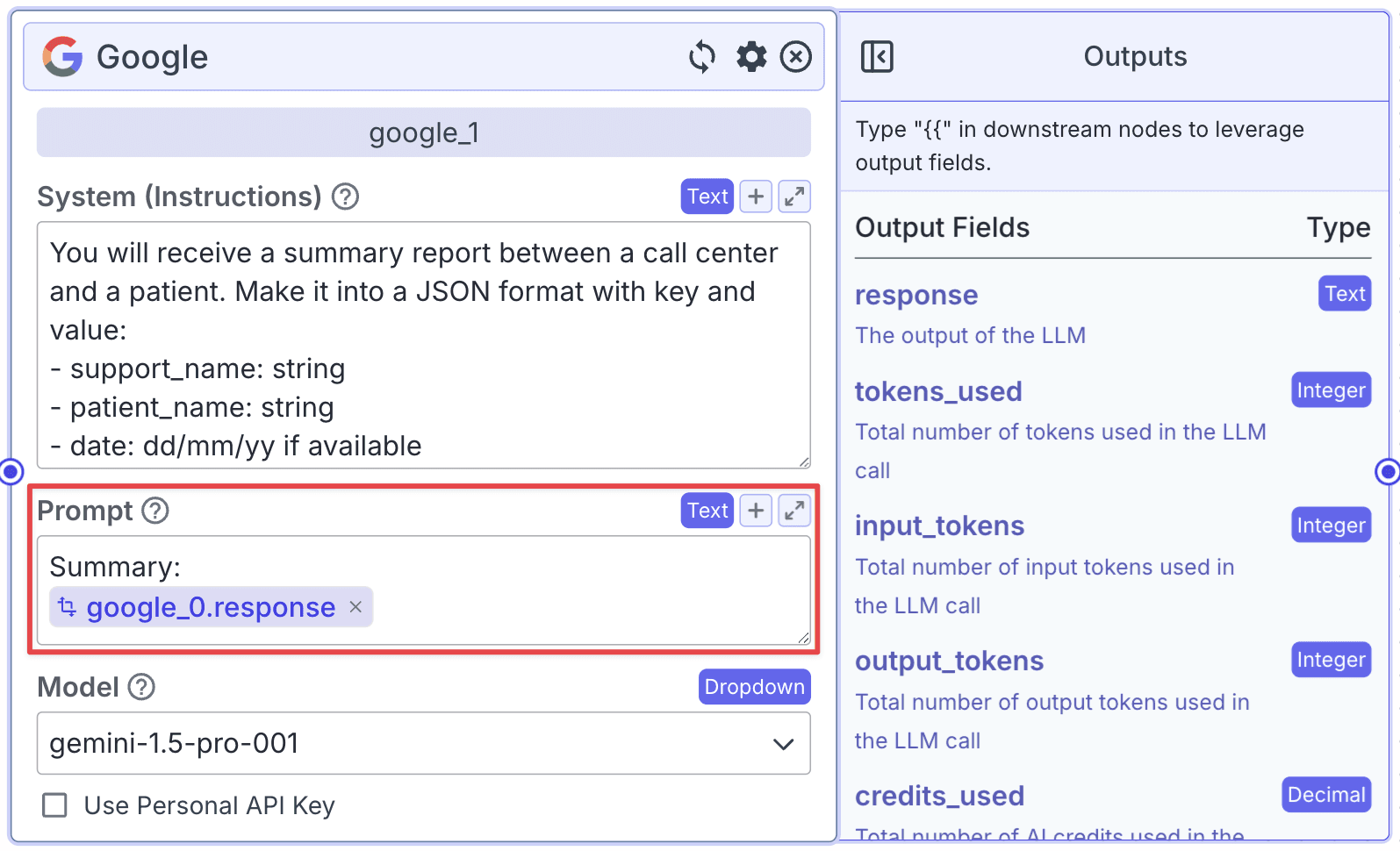
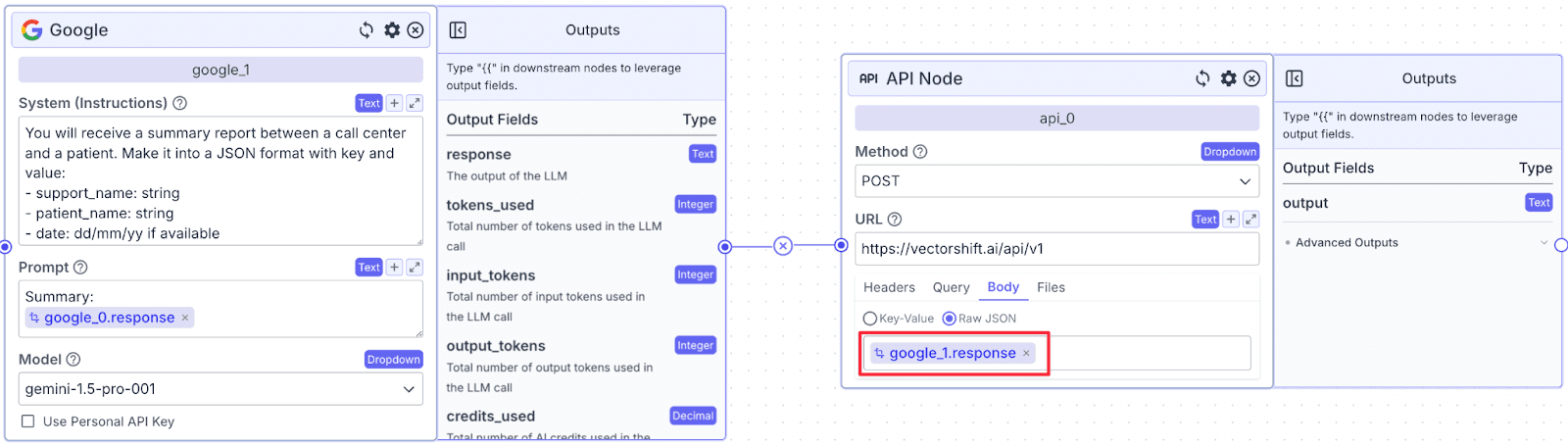
API Node
The last node we need to add is an API Node. Connect the 2nd Google LLM to the API node as a “Body” and choose “Raw JSON”. Additionally, you can change the “Method” and “URL” rows based on your database.
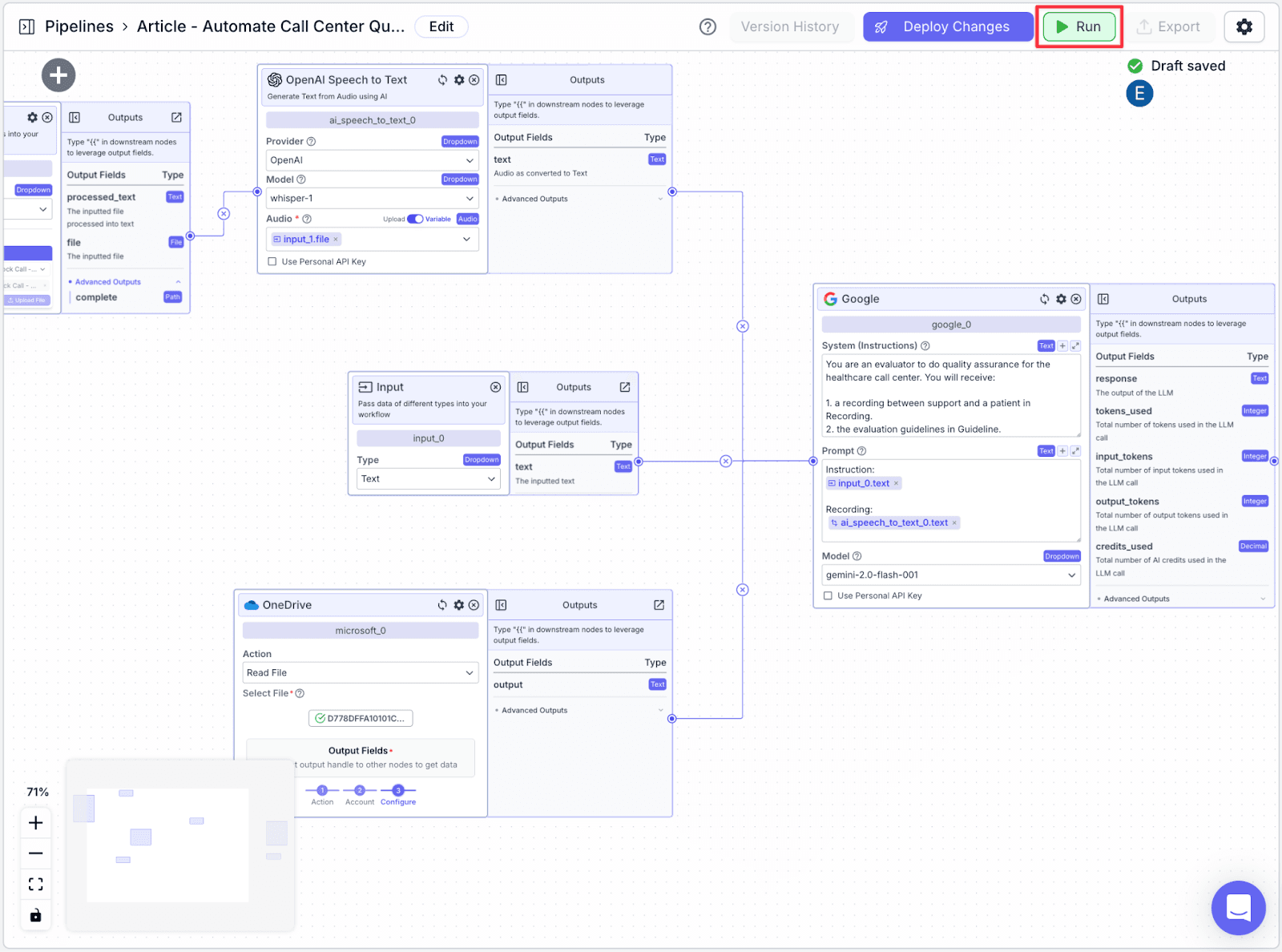
Running the Pipeline
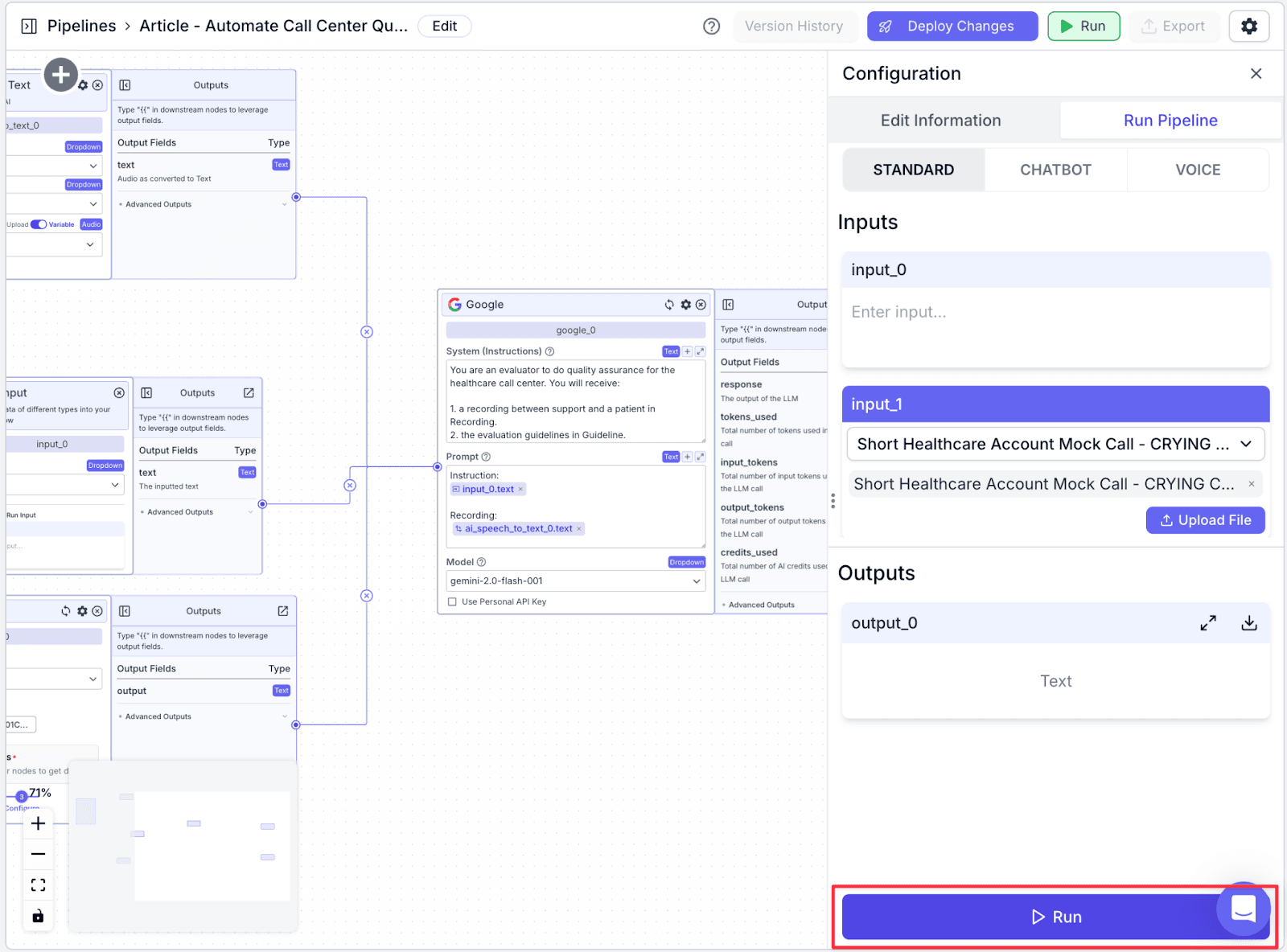
Step 1: Click “Run” on the top-right of the window. You will be shown the “Run Pipeline” pane.
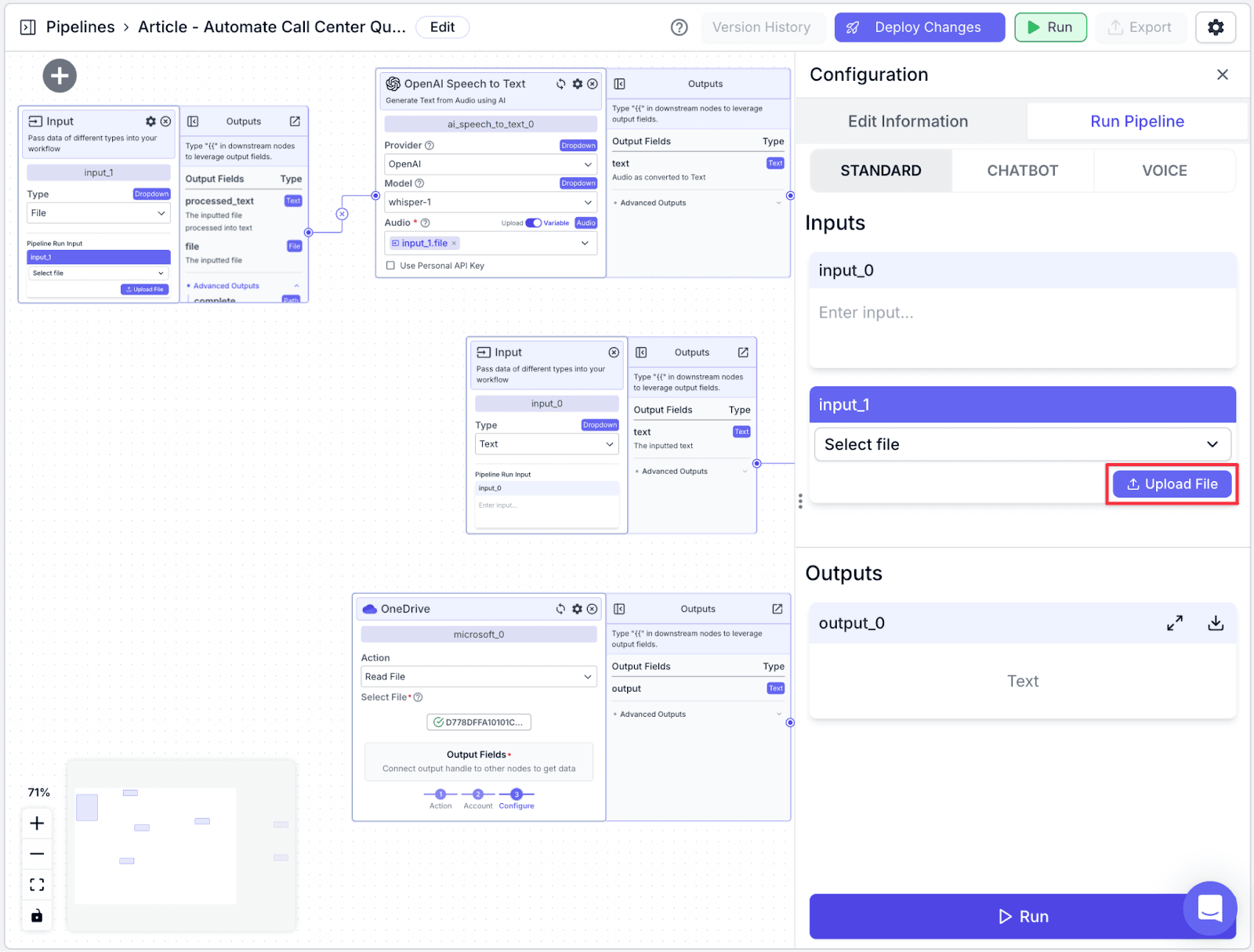
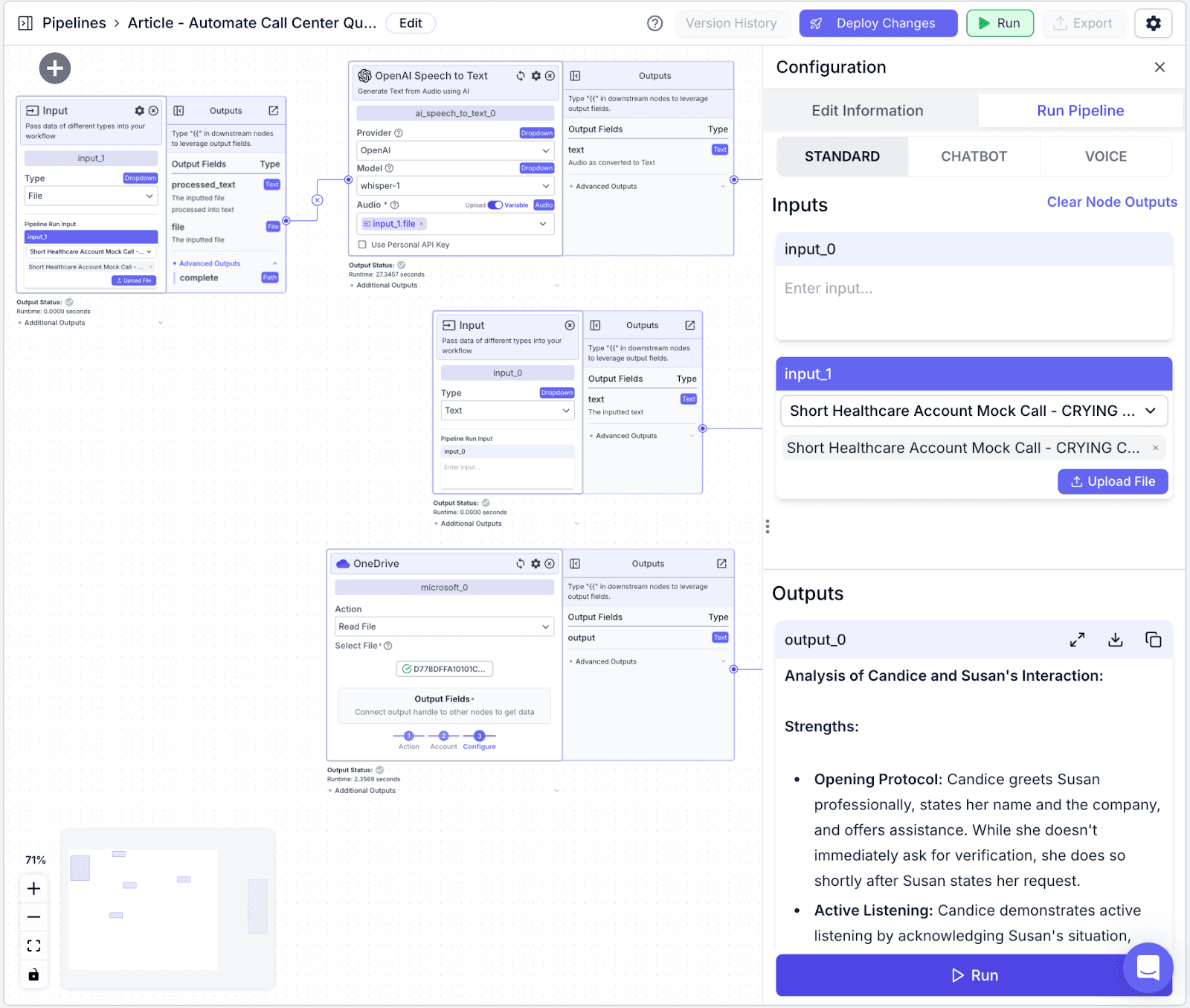
Step 2: Upload a sample recording by clicking “Upload File”. Then, click “Run” on the bottom-right of the pane. You will see the result in the “Outputs” section, the created file in OneDrive, and data added to your database.
Deploying the Pipeline
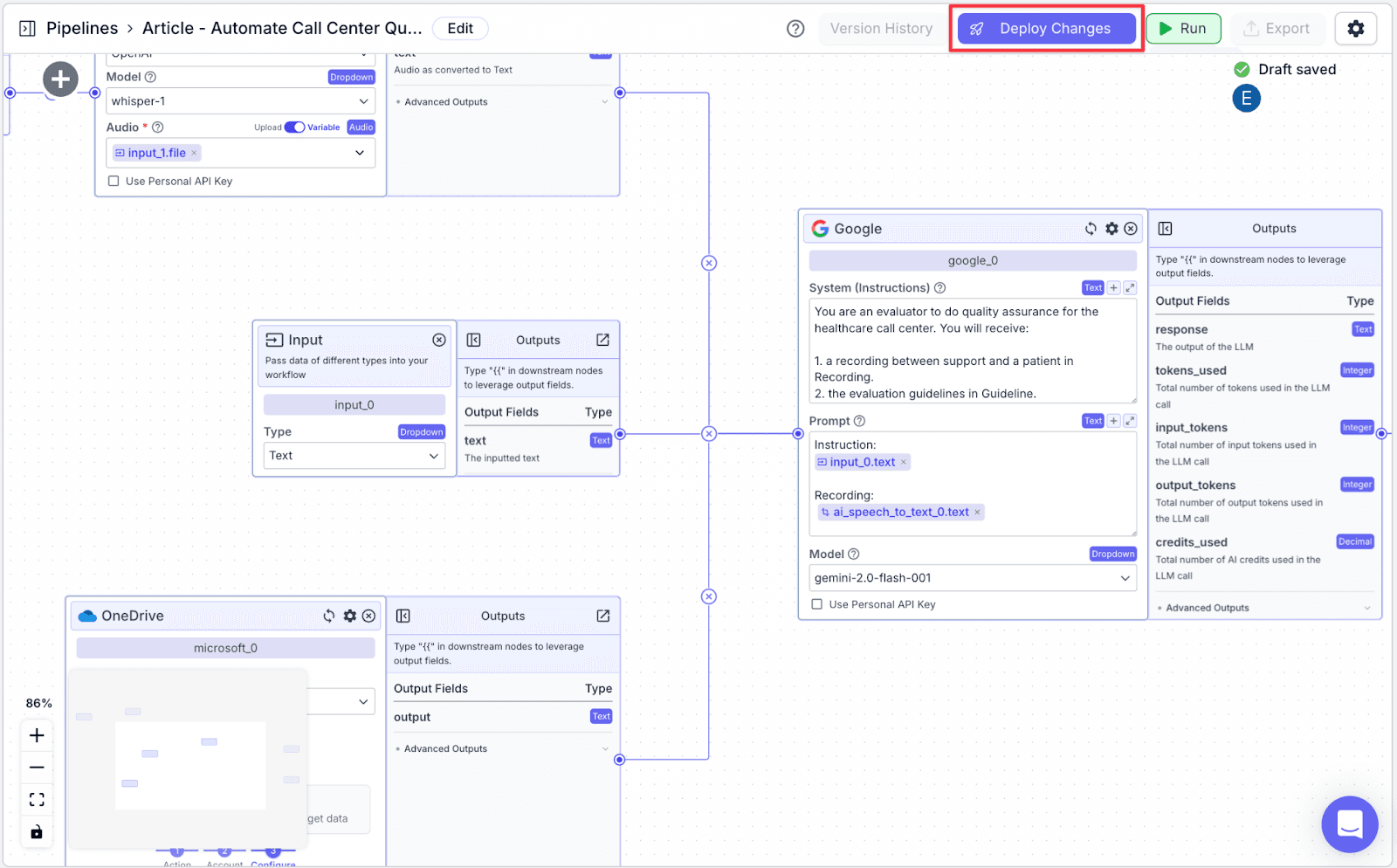
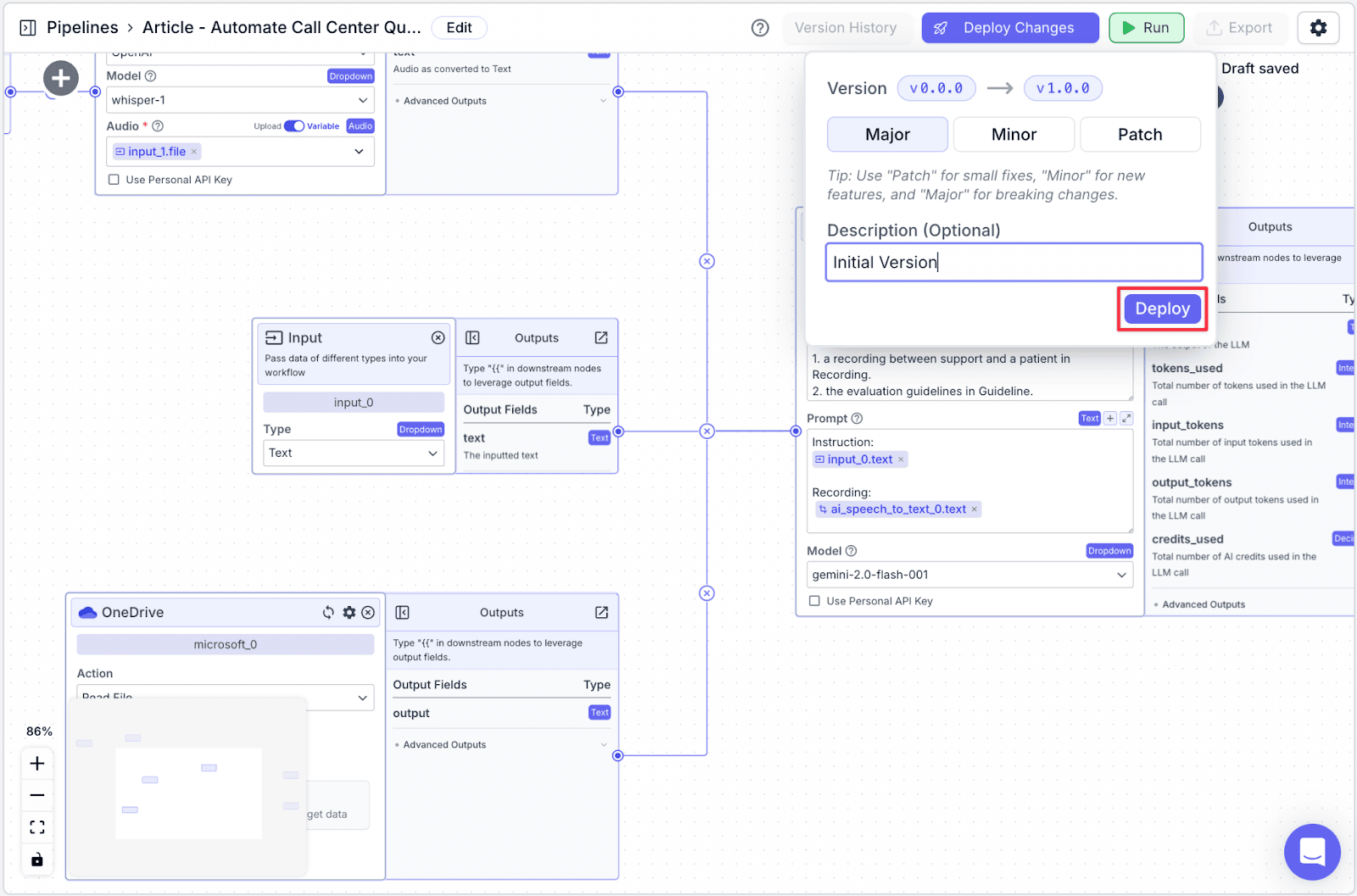
The last thing you need to do is to deploy the pipeline. This allows you to track your pipeline versioning in case you want to revert to the previous version. Click “Deploy Changes” on the top right and click “Deploy”.
2. Exporting the Pipeline
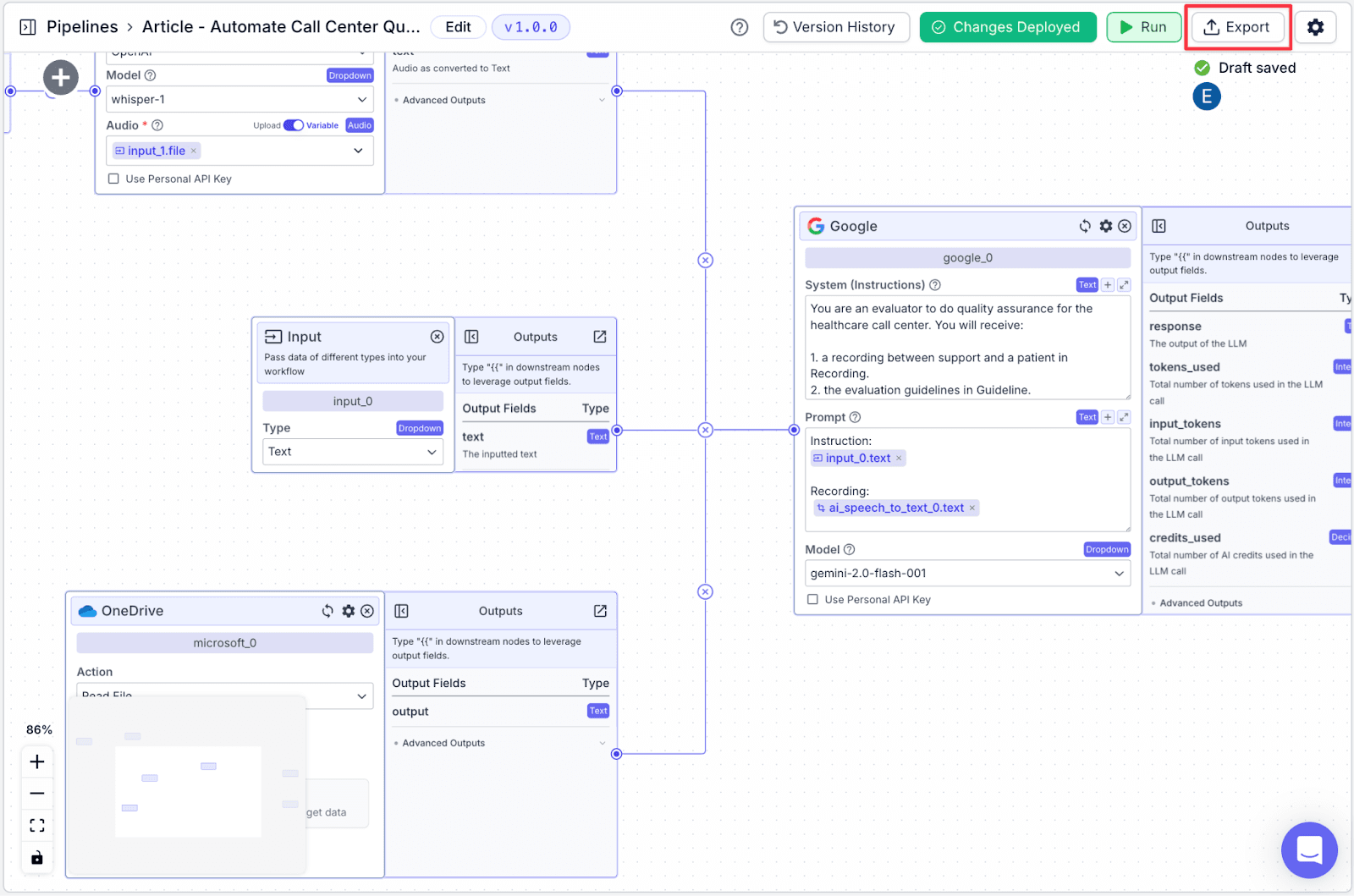
Exporting a pipeline is the easiest way to publish the pipeline so an evaluator can interact with it. In this case, we will export the pipeline into a form.
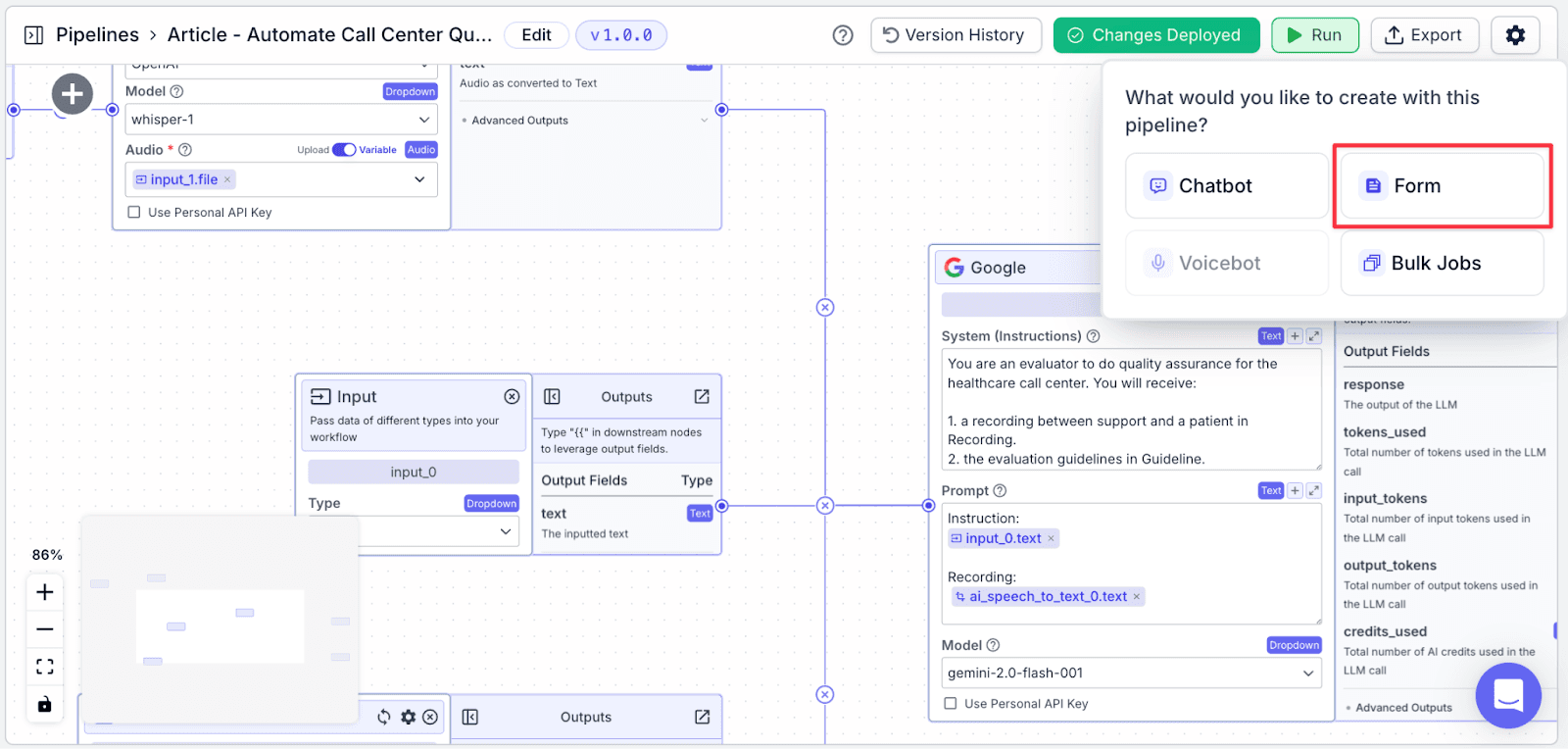
Step 1: After finishing with deployment, click on “Export” and select “Form”.
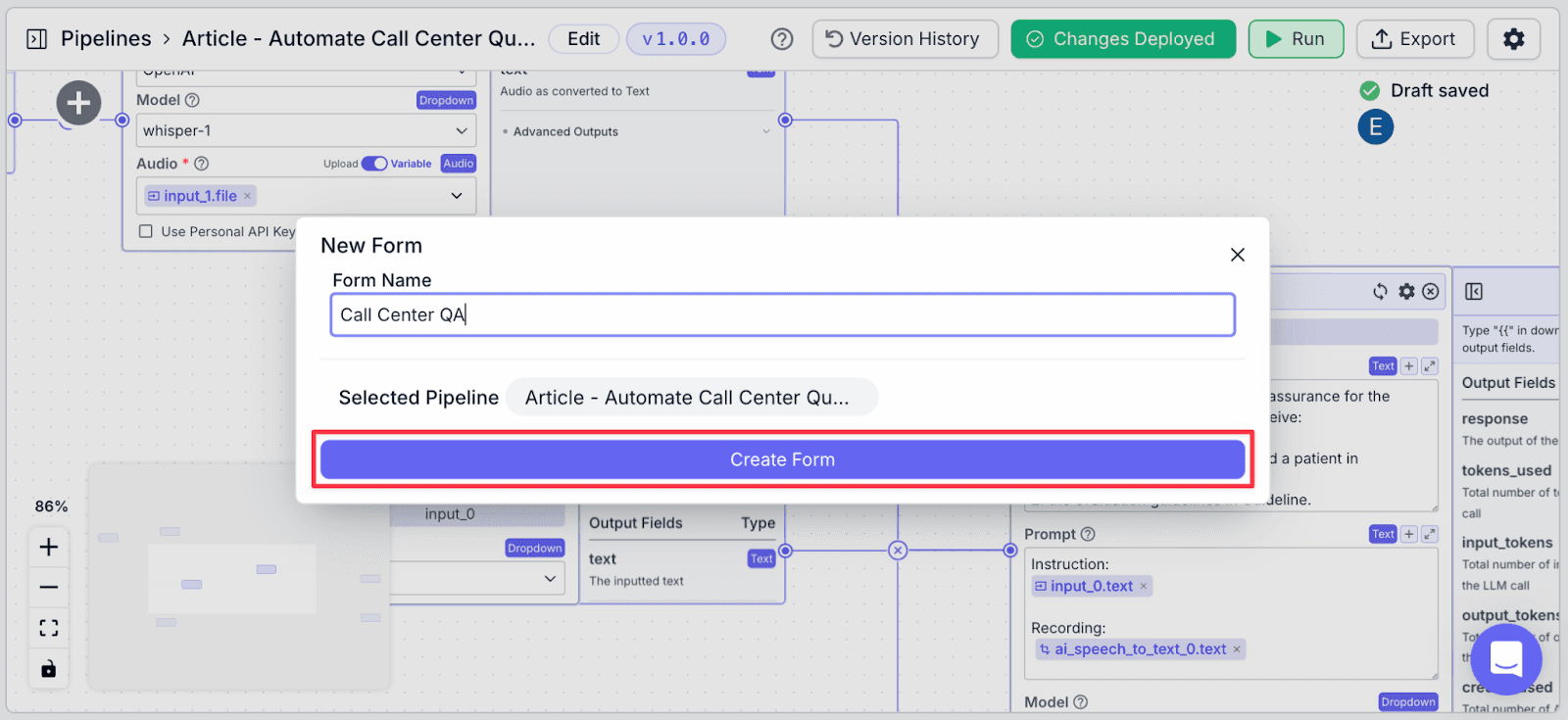
Step 2: Give a name to the form and click “Create Form”
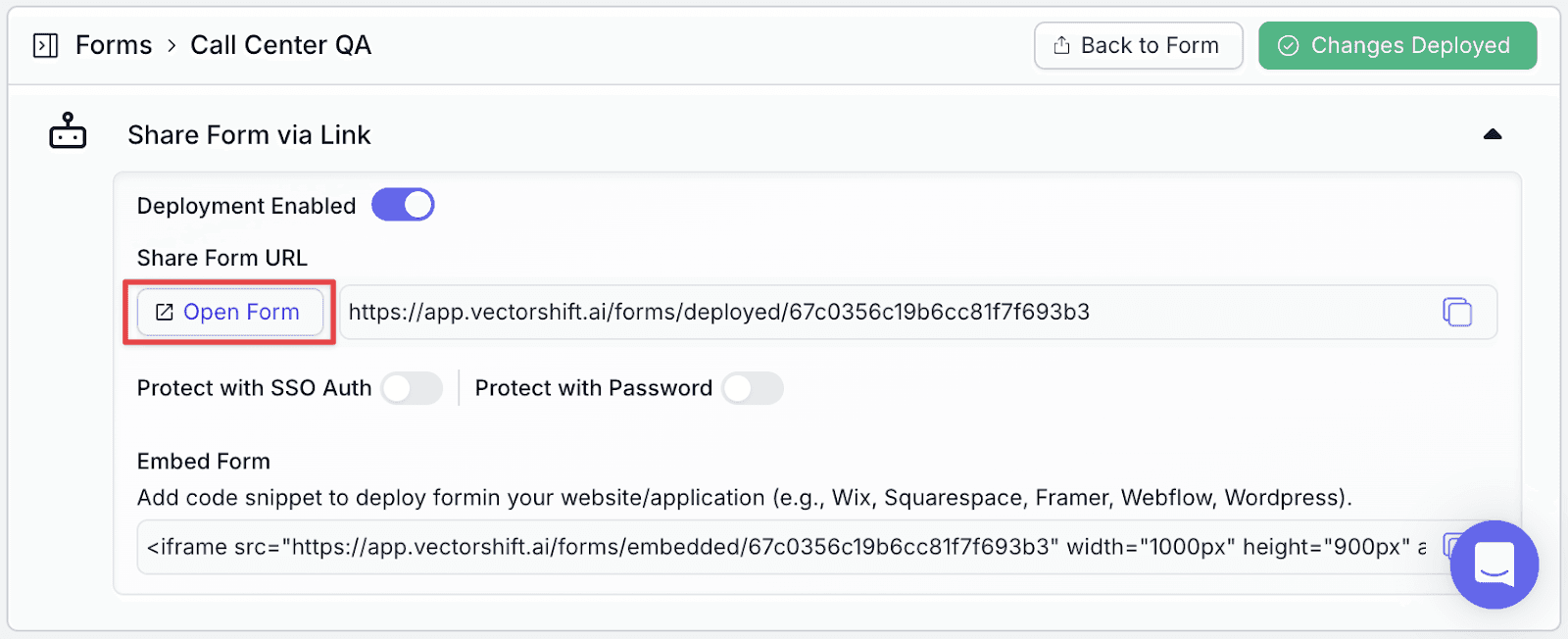
Step 3: Make necessary cosmetic changes to the form and click “Deploy Changes”. Then, click “Export”.
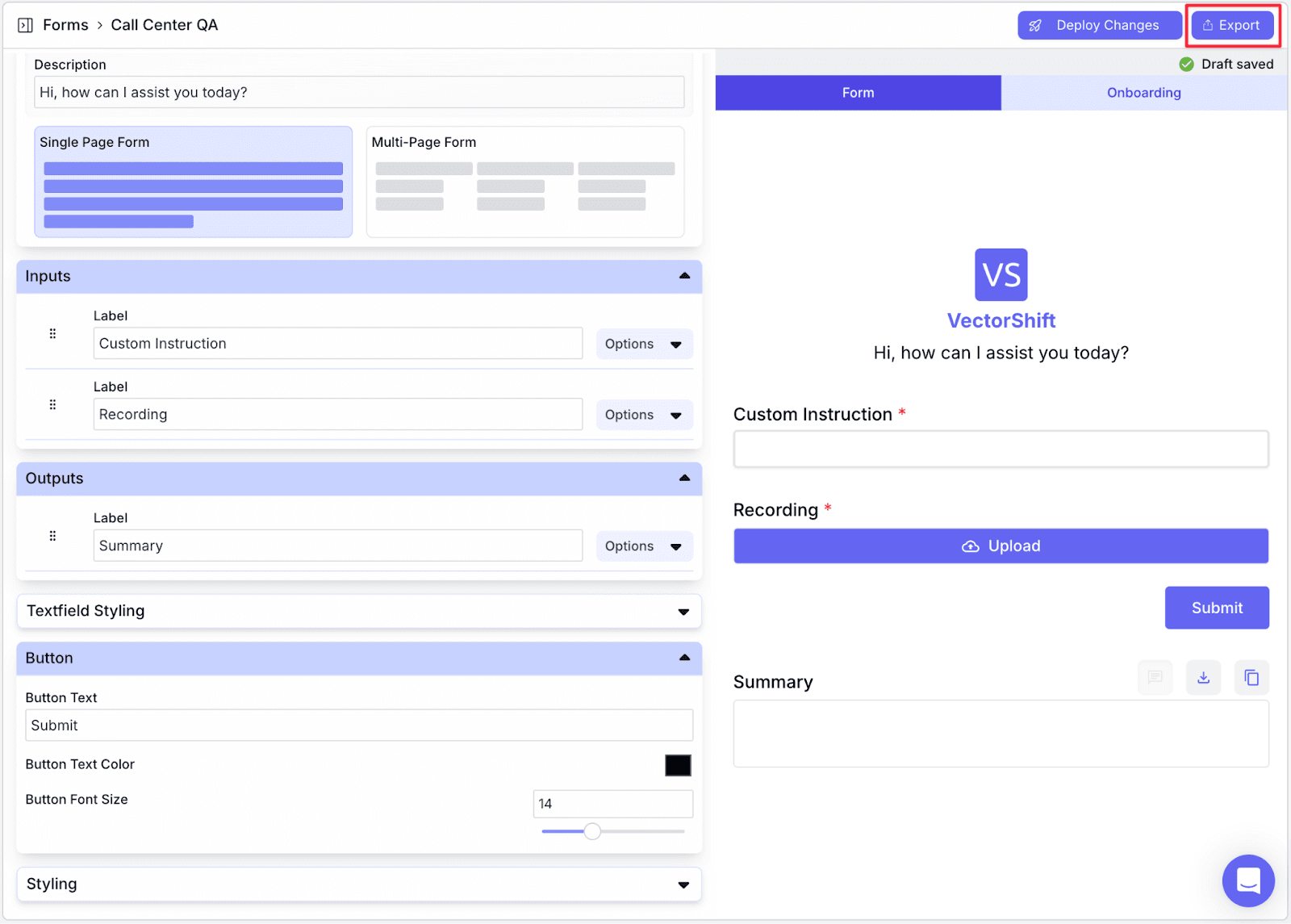
Step 4: Click on “Open Form” to see the export result.
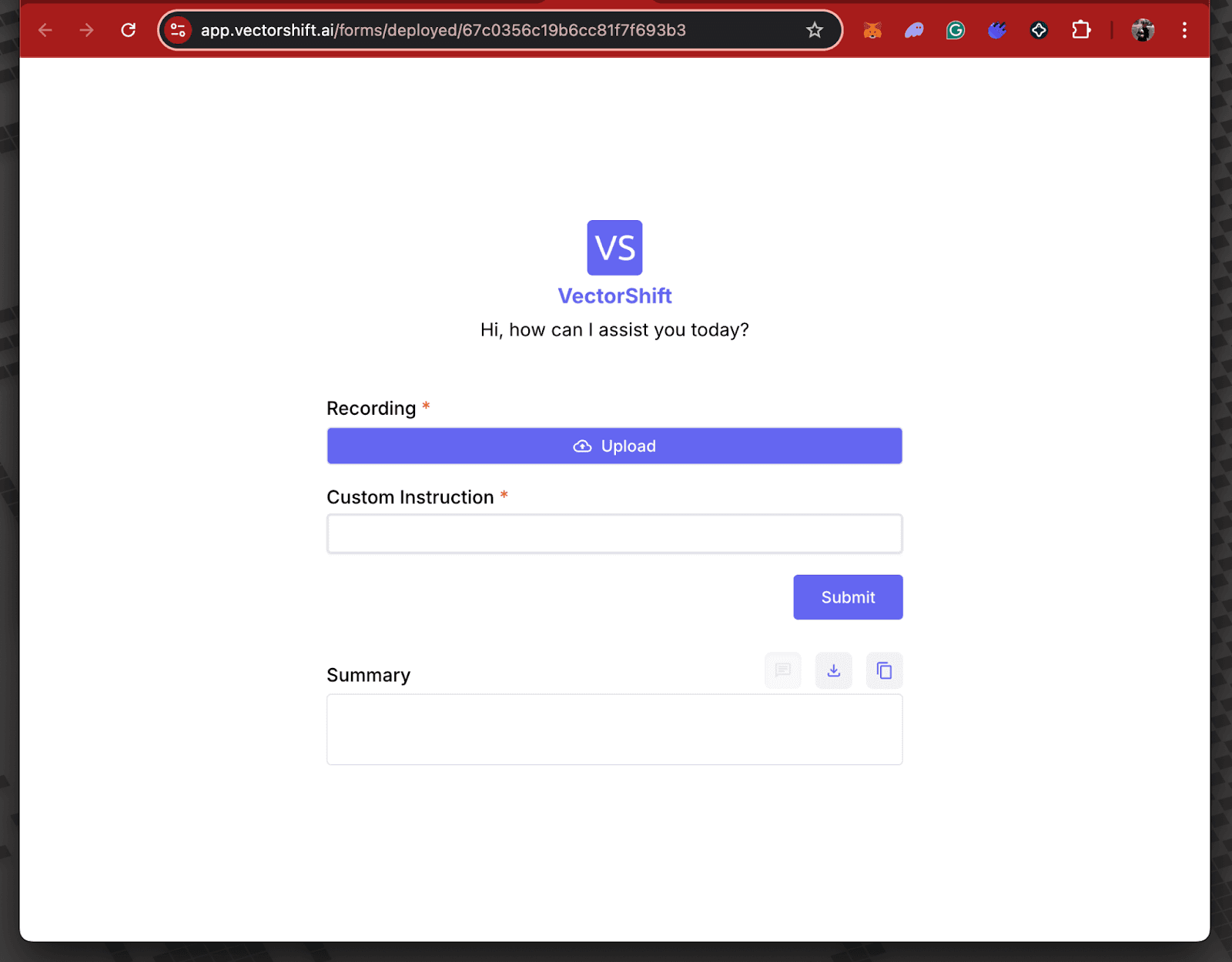
Conclusion
By automating call center QA, organizations can redirect QA budgets toward innovation and customer experience improvements. Curious about the potential savings? Contact us for a customized ROI analysis and to learn how AI can improve your customer experience.

Albert Mao
Co-Founder
Albert Mao is a co-founder of VectorShift, a no-code AI automation platform and holds a BA in Statistics from Harvard. Previously, he worked at McKinsey & Company, helping Fortune 500 firms with digital transformation and go-to-market strategies.


